
In January Stuart Marks published a blog post named “Processing Large Files in Java” as a response to a post by Paige Niedringhaus about “Using Java to Read Really, Really Large Files”. Niedringhaus there reports her experience with JavaScript to solve a “coding challenge” where a “very large file” has to be processed and four specific questions where asked about the processed file. After solving the challenge in JavaScript, Niedringhaus then moved forward and successfully implemented a solution to the challenge in Java as she was curious about Java and how to do it in that language.
This article starts where Marks left and tries to improve on the performance aspect of the code further; until we hit the wall.
Objectives
In this article we discover how to implement a challenges solution in Go and then increase performance by 650% going below 4 seconds from 25 seconds, which is over 20x improvement from the challenges original version of 84 seconds over the course of 9 revisions. We’ll also have a look at performance limiting aspects of this challenge.
Performance is our priority for now. Marks and others pointed out that code quality can be equally important. Thats very true and Niedringhaus’s first implementation was “just” about how to solve the challenge and not about performance; that became a focus when other solutions where available to her. For a program to run such a long time, nearly one an a half minute, it is a valid thing to measure its performance and then compare it to the code that lead to this perfomance. With that measurement we can at least quantify a quality of the code.
But lets first get an overview about the challenge, have a short look at two existing implementations and then create a first port of the fastest of those implementations to Go.
The Challenge
The mission statement of the challenge is written as
c1 – Write a program that will print out the total number of lines in the file.
c2 – Notice that the 8th column contains a person’s name. Write a program that loads in this data and creates an array with all name strings. Print out the 432nd and 43243rd names.
c3 – Notice that the 5th column contains a form of date. Count how many donations occurred in each month and print out the results.
c4 – Notice that the 8th column contains a person’s name. Create an array with each first name. Identify the most common first name in the data and how many times it occurs.
(we name the challenges here to make them referenceable later)
The dataset to be processed is freely available data about “Campain Finance Election Contributions by individuals” provided by the U.S. Federal Elections Commission and about 3.3GB in size uncompressed.
Baseline – 7 Iterations in Java
In his article, Marks takes the opportunity to analyse Niedringhaus' Java implementation and “focus on changing aspects of the computation to improve runtime performance” and also to “present some interesting opportunities for optimizations and use of newer APIs”. Overall, Marks establishes a performance baseline for his environment, transforms the given Java programm using his knowledge of Java and reduces the programs runtime by factor of about 3.4x from 108 seconds down to 32 seconds in the course of seven iterations.
After reading Marks article I started to think of how to implement that challenges solution in Go and where we can go in terms of its performance.
Before we start, we set ourselves a baseline by executing the existing implementations given by Niedringhaus and Marks and run them on our environment, a 2017 MacBookPro (Model 14,3, I7-7920HQ) laptop.
| Author | Implementation | Duration [s] | VM Version |
|---|---|---|---|
| Niedringhaus | Java – BufferedReader | 84 | openjdk version “11.0.2” 2019-01-15 |
| Marks | Java – Variation7 | 23 | openjdk version “11.0.2” 2019-01-15 |
The dataset was taken at the 4th of January 2019 and has 18'245'416 lines of ASCII text data. Its SHA1 sum is: 0093f547b28f6c897c81bc3865b28a723a497847.
Check also Implementations of Others that where done after Marks' initial post and after I started with my article. These articles are interesting for their comparing runtime but also for their differences in methods, libraries and languages they used for their implementation.
9 Revisions in Go
After setting up the baseline for performance comparisons we port Marks' fastest implementation and then go through nine revisions of Go code. During these revisions we’ll find interesting aspects that influence the performance in terms of their runtime as well as of their memory-consumption and -behaviour.
I don’t keep it back that we’re driven by plain performance interests at first, making this thing as fast as possible. On the way down to low single digit seconds performance we take different roads of techniques available only to get to a point where we “hit the wall” and get some surprising insights whats happening there. Stay tuned!
Revision 0 – A Go Port
readfile0.go is a straightforward port from Variation7 in Java to Go. We use no external libraries throughout this article. For certain constructs we don’t have a library or utility like Java’s Stream utilities at all, so we have to implement them using Go’s builtin types or the standard library.
For this challenge the given solution can be divided into three sections
- opening the file and defining variables and lists
- reading the file and processing it line by line
- calculate and report what was found
In the first section, Lines 17–28, we define all lists and variables needed to collect data in section 2. Then we use Go’s bufio.Scanner to read and tokenize the given file line by line. We also use a regexp here to parse firstnames in the 8th column of the line.
The 2nd section, Lines 31–48, first parses the whole name from column 8 using strings.SplitN and then appends it to the names list. If we find a first name with the regexp it is also collected to the firstNames list. Last, we take the 5th column and parse it as a year-month string (“2017-10”) and append it to the dates list.
After all lines are processed, the third section, Lines 50-83, then analyses and reports according to the challenges given tasks (c1-c4). Reporting c1: total number of lines of the processed file is easy. Then as the challenges c2 states, we have to report three names at the indexes 0, 432 and 43243. Next a frequency table of the donations has to be made by each month over the years.
The Java implementation uses a sequence of stream processing utilities (java.util.stream.Collectors.groupingBy(…)) that we don’t have in Go to get the donation dates frequencies. Instead we use a map of strings to ints and count up donation dates occurrences by iterating over the dates list and report them according to c3. Last, for c4, the most common donators firstname has to be reported. Similarly to the donations dates, we use a map of strings to integers and iterate over the firstnames found in section two. During that process we note the most common name and its count that then gets reported.
1package main
2
3import (
4 "bufio"
5 "fmt"
6 "log"
7 "os"
8 "path/filepath"
9 "regexp"
10 "strings"
11 "time"
12)
13
14func main() {
15 start := time.Now()
16
17 file, err := os.Open(os.Args[1])
18 if err != nil {
19 log.Fatal(err)
20 }
21 defer file.Close()
22
23 firstNamePat := regexp.MustCompile(", \\s*([^, ]+)")
24 names := make([]string, 0)
25 firstNames := make([]string, 0)
26 dates := make([]string, 0)
27 commonName := ""
28 commonCount := 0
29
30 scanner := bufio.NewScanner(file)
31 for scanner.Scan() {
32 text := scanner.Text()
33
34 // get all the names
35 split := strings.SplitN(text, "|", 9) // 10.95
36 name := strings.TrimSpace(split[7])
37 names = append(names, name)
38
39 // extract first names
40 if matches := firstNamePat.FindAllStringSubmatch(name, 1); len(matches) > 0 {
41 firstNames = append(firstNames, matches[0][1])
42 }
43
44 // extract dates
45 chars := strings.TrimSpace(split[4])[:6]
46 date := chars[:4] + "-" + chars[4:6]
47 dates = append(dates, date)
48 }
49
50 // report c2: names at index
51 fmt.Printf("Name: %s at index: %v\n", names[0], 0)
52 fmt.Printf("Name: %s at index: %v\n", names[432], 432)
53 fmt.Printf("Name: %s at index: %v\n", names[43243], 43243)
54 fmt.Printf("Name time: %v\n", time.Since(start))
55
56 // report c1: total number of lines
57 fmt.Printf("Total file line count: %v\n", len(names))
58 fmt.Printf("Line count time: : %v\n", time.Since(start))
59
60 // report c3: donation frequency
61 dateMap := make(map[string]int)
62 for _, date := range dates {
63 dateMap[date] += 1
64 }
65 for k, v := range dateMap {
66 fmt.Printf("Donations per month and year: %v and donation count: %v\n", k, v)
67 }
68 fmt.Printf("Donations time: : %v\n", time.Since(start))
69
70 // report c4: most common firstName
71 nameMap := make(map[string]int)
72 ncount := 0 // new count
73 for _, name := range firstNames {
74 ncount = nameMap[name] + 1
75 nameMap[name] = ncount
76 if ncount > commonCount {
77 commonName = name
78 commonCount = ncount
79 }
80 }
81
82 fmt.Printf("The most common first name is: %s and it occurs: %v times.\n", commonName, commonCount)
83 fmt.Printf("Most common name time: %v\n", time.Since(start))
84 fmt.Fprintf(os.Stderr, "revision: %v, runtime: %v\n", filepath.Base(os.Args[0]), time.Since(start))
85}
17 file, err := os.Open(os.Args[1])
18 if err != nil {
19 log.Fatal(err)
20 }
21 defer file.Close()
22
23 firstNamePat := regexp.MustCompile(", \\s*([^, ]+)")
24 names := make([]string, 0)
25 firstNames := make([]string, 0)
26 dates := make([]string, 0)
27 commonName := ""
28 commonCount := 0
31 for scanner.Scan() {
32 text := scanner.Text()
33
34 // get all the names
35 split := strings.SplitN(text, "|", 9) // 10.95
36 name := strings.TrimSpace(split[7])
37 names = append(names, name)
38
39 // extract first names
40 if matches := firstNamePat.FindAllStringSubmatch(name, 1); len(matches) > 0 {
41 firstNames = append(firstNames, matches[0][1])
42 }
43
44 // extract dates
45 chars := strings.TrimSpace(split[4])[:6]
46 date := chars[:4] + "-" + chars[4:6]
47 dates = append(dates, date)
48 }
50 // report c2: names at index
51 fmt.Printf("Name: %s at index: %v\n", names[0], 0)
52 fmt.Printf("Name: %s at index: %v\n", names[432], 432)
53 fmt.Printf("Name: %s at index: %v\n", names[43243], 43243)
54 fmt.Printf("Name time: %v\n", time.Since(start))
55
56 // report c1: total number of lines
57 fmt.Printf("Total file line count: %v\n", len(names))
58 fmt.Printf("Line count time: : %v\n", time.Since(start))
59
60 // report c3: donation frequency
61 dateMap := make(map[string]int)
62 for _, date := range dates {
63 dateMap[date] += 1
64 }
65 for k, v := range dateMap {
66 fmt.Printf("Donations per month and year: %v and donation count: %v\n", k, v)
67 }
68 fmt.Printf("Donations time: : %v\n", time.Since(start))
69
70 // report c4: most common firstName
71 nameMap := make(map[string]int)
72 ncount := 0 // new count
73 for _, name := range firstNames {
74 ncount = nameMap[name] + 1
75 nameMap[name] = ncount
76 if ncount > commonCount {
77 commonName = name
78 commonCount = ncount
79 }
80 }
81
82 fmt.Printf("The most common first name is: %s and it occurs: %v times.\n", commonName, commonCount)
83 fmt.Printf("Most common name time: %v\n", time.Since(start))
Source code is presented from now on always in their entire length but accomodated by snippets of lines and also a diff-file. Sometimes and where applicable lines are highlighted. Unfortunately the Highlighter I use here has a bug, an Go code sometimes is slightly wrong intended, especially after line-comments
Revision 0 – Performance
Lets run this first revision and see how it performs.
$ go run rev0/readfile0.go itcont.txt
Most common name time: 24.976828s
$
Just below 25 seconds, that’s interesting! Lets see how the output compares to Variation7.
1Name: PEREZ, JOHN A at index: 0
2Name: MILESKI, JOHN A at index: 432
3Name: COX, JOHN MARTIN at index: 43243
4Name time: 29.957748306s
5Total file line count: 18245416
6Line count time: 29.957770809s
7Donations per month and year: 2018-10 and donation count: 2615902
8Donations per month and year: 2018-04 and donation count: 3033610
9Donations per month and year: 2018-06 and donation count: 496569
10Donations per month and year: 2018-02 and donation count: 765317
11Donations per month and year: 2017-08 and donation count: 298740
12Donations per month and year: 2017-12 and donation count: 486447
13Donations per month and year: 2018-07 and donation count: 1105070
14Donations per month and year: 2018-09 and donation count: 1264597
15Donations per month and year: 2018-11 and donation count: 302025
16Donations per month and year: 2017-02 and donation count: 36367
17Donations per month and year: 2017-03 and donation count: 78664
18Donations per month and year: 2017-10 and donation count: 585708
19Donations per month and year: 2018-05 and donation count: 533304
20Donations per month and year: 2018-01 and donation count: 1252689
21Donations per month and year: 2017-07 and donation count: 768051
22Donations per month and year: 2017-09 and donation count: 377544
23Donations per month and year: 2018-03 and donation count: 271267
24Donations per month and year: 2017-06 and donation count: 180699
25Donations per month and year: 2017-11 and donation count: 346019
26Donations per month and year: 2017-01 and donation count: 21
27Donations per month and year: 2017-05 and donation count: 197636
28Donations per month and year: 2017-04 and donation count: 254810
29Donations per month and year: 2018-12 and donation count: 2259957
30Donations per month and year: 2018-08 and donation count: 733865
31Donations per month and year: 2019-01 and donation count: 538
32Donations time: 30.339466074s
33The most common first name is: JOHN and it occurs: 475350 times.
34Most common name time: 33.686980274s
1Name: PEREZ, JOHN A at index: 0
2Name: MILESKI, JOHN A at index: 432
3Name: COX, JOHN MARTIN at index: 43243
4Name time: 22136ms
5Total file line count: 18245416
6Line count time: 22152ms
7Donations per month and year: 2018-04 and donation count: 3033610
8Donations per month and year: 2018-05 and donation count: 533304
9Donations per month and year: 2018-06 and donation count: 496569
10Donations per month and year: 2018-07 and donation count: 1105070
11Donations per month and year: 2017-10 and donation count: 585708
12Donations per month and year: 2018-01 and donation count: 1252689
13Donations per month and year: 2017-11 and donation count: 346019
14Donations per month and year: 2018-02 and donation count: 765317
15Donations per month and year: 2017-12 and donation count: 486447
16Donations per month and year: 2018-03 and donation count: 271267
17Donations per month and year: 2018-08 and donation count: 733865
18Donations per month and year: 2018-09 and donation count: 1264597
19Donations per month and year: 2017-03 and donation count: 78664
20Donations per month and year: 2017-04 and donation count: 254810
21Donations per month and year: 2017-05 and donation count: 197636
22Donations per month and year: 2017-06 and donation count: 180699
23Donations per month and year: 2018-11 and donation count: 302025
24Donations per month and year: 2019-01 and donation count: 538
25Donations per month and year: 2018-12 and donation count: 2259957
26Donations per month and year: 2017-01 and donation count: 21
27Donations per month and year: 2017-02 and donation count: 36367
28Donations per month and year: 2018-10 and donation count: 2615902
29Donations per month and year: 2017-07 and donation count: 768051
30Donations per month and year: 2017-08 and donation count: 298740
31Donations per month and year: 2017-09 and donation count: 377544
32Donations time: 22781ms
33The most common first name is: JOHN and it occurs: 475350 times.
34Most common name time: 23881ms
We get the same output regarding its format. And with 25 seconds we’re 8% slower than Variation7.
Lets close this section of the first revision for now. We will now go through several steps of optimization (and sometimes non-optimization) and try to get as low as possible from a performance perspective.
At the end I’ll present performance data for all revisions in detail. For each revision the revisions best runtime will be noted so we get an indication where we are. Beside plain runtime we’ll also inspect the total memory allocation as we as the allocated heap- and system memory.
A Plan to Go Forward
With Revision 0 we are 8% slower than the run-time of Variation7. One can say that readline0.go is a fairly simple and readable Go program. It is implemented in one function, like its predecessors, and has a simple linear non-parallel structure. There is no explicit parallelism or concurrency going on during its runtime (actually the GC is doing its work concurrently but thats out of our control for now).
Concurrency in Go – When Go entered the attention of the programming language and computing communities, it was presented as a simple and programming efficiency oriented langugage. It also had some features to be prepared for the then coming multi-core environments. Coming from Google and with its concept of goroutines and channels backed right into the language (inspired by Tony Hoares Communicating Sequential Processes, CSP) it was ready to be a language for a network-computing oriented audience (The term Cloud then was not invented yet). Concurrency is and was a thing for Go, not parallelism. Concurrency in Go is more like a tool to structural composition, not doing stuff in parallel even it it can be used to do that.
Why talking about concurrency and parallelism here? Sometimes Go newcomers tend to improve lacking performance by using Go’s goroutines and channels just to get better performance. Programmers from other languages do the same and “go parallel” using multi-threading to get work distributed to their multicore CPUs. There is nothing wrong by doing more work at the same time, but it can lead to other problems when the communication overhead kicks in and limits its intended performance gain. Writing this, we now will go ahead and kind of naively apply Go’s concurrency features to our problem; and see what happens.
Revision 1 – A Naive Performance Improvement
If we think about the structure of our challenges solution, where could we improve performance? We read lines of data, process them, store them in lists and then process them to get a report. So if we try to process these parts of our programs structure in parallel, why not use Go’s goroutines and let them communicate through channels. This is what we try to do with Revision 1 – readfile1.go
- start a goroutine reading from three channels
nameC, lastnameC, datesCto append lists - for each line, start a goroutine for every line and parse 3 fields to send them over to one of these three channels
- wait until all goroutines are finished
- report according to the challenges rules (c1-c4)
After reading a line of the dataset, we start a goroutine Lines 59-76 where we parse the three fields we’re interested in (name, lastname, donation date) and send those fields over to a concurrently runnning goroutine Lines 34-54 which collects those fields and appends them to their corresponding lists.
59 go func() {
60 // get all the names
61 split := strings.SplitN(text, "|", 9)
62 name := strings.TrimSpace(split[7])
63 namesC <- name
64
65 // extract first names
66 if matches := firstNamePat.FindAllStringSubmatch(name, 1); len(matches) > 0 {
67 firstNamesC <- matches[0][1]
68 } else {
69 wg.Add(-1)
70 }
71
72 // extract dates
73 chars := strings.TrimSpace(split[4])[:6]
74 date := chars[:4] + "-" + chars[4:6]
75 datesC <- date
76 }()
34 go func() {
35 for {
36 select {
37 case n, ok := <-namesC:
38 if ok {
39 names = append(names, n)
40 wg.Done()
41 }
42 case fn, ok := <-firstNamesC:
43 if ok {
44 firstNames = append(firstNames, fn)
45 wg.Done()
46 }
47 case d, ok := <-datesC:
48 if ok {
49 dates = append(dates, d)
50 wg.Done()
51 }
52 }
53 }
54 }()
1package main
2
3import (
4 "bufio"
5 "fmt"
6 "log"
7 "os"
8 "regexp"
9 "strings"
10 "sync"
11 "time"
12)
13
14func main() {
15 start := time.Now()
16 file, err := os.Open(os.Args[1])
17 if err != nil {
18 log.Fatal(err)
19 }
20 defer file.Close()
21
22 firstNamePat := regexp.MustCompile(", \\s*([^, ]+)")
23 names := make([]string, 0)
24 firstNames := make([]string, 0)
25 dates := make([]string, 0)
26 commonName := ""
27 commonCount := 0
28 scanner := bufio.NewScanner(file)
29 namesC := make(chan string)
30 firstNamesC := make(chan string)
31 datesC := make(chan string)
32 wg := sync.WaitGroup{}
33
34 go func() {
35 for {
36 select {
37 case n, ok := <-namesC:
38 if ok {
39 names = append(names, n)
40 wg.Done()
41 }
42 case fn, ok := <-firstNamesC:
43 if ok {
44 firstNames = append(firstNames, fn)
45 wg.Done()
46 }
47 case d, ok := <-datesC:
48 if ok {
49 dates = append(dates, d)
50 wg.Done()
51 }
52 }
53 }
54 }()
55
56 for scanner.Scan() {
57 text := scanner.Text()
58 wg.Add(3)
59 go func() {
60 // get all the names
61 split := strings.SplitN(text, "|", 9)
62 name := strings.TrimSpace(split[7])
63 namesC <- name
64
65 // extract first names
66 if matches := firstNamePat.FindAllStringSubmatch(name, 1); len(matches) > 0 {
67 firstNamesC <- matches[0][1]
68 } else {
69 wg.Add(-1)
70 }
71
72 // extract dates
73 chars := strings.TrimSpace(split[4])[:6]
74 date := chars[:4] + "-" + chars[4:6]
75 datesC <- date
76 }()
77 }
78 wg.Wait()
79 close(namesC)
80 close(firstNamesC)
81 close(datesC)
82
83 // report c2: names at index
84 fmt.Printf("Name: %s at index: %v\n", names[0], 0)
85 fmt.Printf("Name: %s at index: %v\n", names[432], 432)
86 fmt.Printf("Name: %s at index: %v\n", names[43243], 43243)
87 fmt.Printf("Name time: %v\n", time.Since(start))
88
89 // report c1: total number of lines
90 fmt.Printf("Total file line count: %v\n", len(names))
91 fmt.Printf("Line count time: %v\n", time.Since(start))
92
93 // report c3: donation frequency
94 dateMap := make(map[string]int)
95 for _, date := range dates {
96 dateMap[date] += 1
97 }
98 for k, v := range dateMap {
99 fmt.Printf("Donations per month and year: %v and donation count: %v\n", k, v)
100 }
101 fmt.Printf("Donations time: %v\n", time.Since(start))
102
103 // report c4: most common firstName
104 nameMap := make(map[string]int)
105 nameCount := 0 // new count
106 for _, name := range firstNames {
107 nameCount = nameMap[name] + 1
108 nameMap[name] = nameCount
109 if nameCount > commonCount {
110 commonName = name
111 commonCount = nameCount
112 }
113 }
114 fmt.Printf("The most common first name is: %s and it occurs: %v times.\n", commonName, commonCount)
115 fmt.Printf("Most common name time: %v\n", time.Since(start))
116}
1--- rev0/readfile0.go 2019-03-30 01:35:01.000000000 +0100
2+++ rev1/readfile1.go 2019-03-30 01:29:26.000000000 +0100
3@@ -7,6 +7,7 @@
4 "os"
5 "regexp"
6 "strings"
7+ "sync"
8 "time"
9 )
10
11@@ -24,26 +25,60 @@
12 dates := make([]string, 0)
13 commonName := ""
14 commonCount := 0
15-
16 scanner := bufio.NewScanner(file)
17- for scanner.Scan() {
18- text := scanner.Text()
19-
20- // get all the names
21- split := strings.SplitN(text, "|", 9)
22- name := strings.TrimSpace(split[7])
23- names = append(names, name)
24-
25- // extract first names
26- if matches := firstNamePat.FindAllStringSubmatch(name, 1); len(matches) > 0 {
27- firstNames = append(firstNames, matches[0][1])
28+ namesC := make(chan string)
29+ firstNamesC := make(chan string)
30+ datesC := make(chan string)
31+ wg := sync.WaitGroup{}
32+
33+ go func() {
34+ for {
35+ select {
36+ case n, ok := <-namesC:
37+ if ok {
38+ names = append(names, n)
39+ wg.Done()
40+ }
41+ case fn, ok := <-firstNamesC:
42+ if ok {
43+ firstNames = append(firstNames, fn)
44+ wg.Done()
45+ }
46+ case d, ok := <-datesC:
47+ if ok {
48+ dates = append(dates, d)
49+ wg.Done()
50+ }
51+ }
52 }
53+ }()
54
55- // extract dates
56- chars := strings.TrimSpace(split[4])[:6]
57- date := chars[:4] + "-" + chars[4:6]
58- dates = append(dates, date)
59+ for scanner.Scan() {
60+ text := scanner.Text()
61+ wg.Add(3)
62+ go func() {
63+ // get all the names
64+ split := strings.SplitN(text, "|", 9)
65+ name := strings.TrimSpace(split[7])
66+ namesC <- name
67+
68+ // extract first names
69+ if matches := firstNamePat.FindAllStringSubmatch(name, 1); len(matches) > 0 {
70+ firstNamesC <- matches[0][1]
71+ } else {
72+ wg.Add(-1)
73+ }
74+
75+ // extract dates
76+ chars := strings.TrimSpace(split[4])[:6]
77+ date := chars[:4] + "-" + chars[4:6]
78+ datesC <- date
79+ }()
80 }
81+ wg.Wait()
82+ close(namesC)
83+ close(firstNamesC)
84+ close(datesC)
85
86 // report c2: names at index
87 fmt.Printf("Name: %s at index: %v\n", names[0], 0)
We decouple the part where we read lines of text from the parts where these lines are processsed and then the data is collected. The decoupling is done by issuing goroutines and connect them back using channels. When layed out to multiple CPU cores the following could happen by reading lines and processing them concurrently on other cores
CPU-0: [read line1][read line2][read line3]
CPU-1: [process line1] [process line3]
CPU-2: [process line2]
which is obiviously more efficient than
CPU-0: [read line1][process line1][read line2][process line2][read line3][process line3]
Lets run Revision 1 and see how it performs.
Performance
Running Revision 1 we get
$ go run rev1/readfile1.go itcont.txt
Most common name time: 732s
$
Thats over 12 minutes! I ran it a 2nd time and it took even longer. What happens here?
We fired off a goroutine that receives names, firstnames and dates from three channels and then for every line of text parsed we spun off an another goroutine and sent over names, firstnames and dates. Thats over 18 million goroutines feeding one other goroutine through three channels and therefore 3x18 million = 54 million messages over those three channels.
send name -> [ nameC ] --\
send firstName -> [ firstNameC ] --- -> select() one -> [ append one to a list ]
send date -> [ datesC ] --/
While we ran Revision 1 the CPU cores where highly saturated with “work”. For every line we fire up a goroutine then gets running and distributed over to all available cores. But it seems that the overhead of communication in relation to the small part of parsing a line into three data fields (firstname, lastname, date) is high and we end up waiting over 12 minutes to get completed.
There is one detail about Channels that also plays against us. Channels, at least non-buffered ones with a capacity of 1, do block when messages are sent to them. A Channel is blocked until the receiving end of it reads the message. The for - select construct seen here is a well known pattern to select over multiple channels and receive from one of them when available.
This way, the sending goroutines have to wait until the draining Channel is receiving the message, either a name, a firstname or a date. This produces a substantional amount of contention.
Go Tracer
Lets run Revision1 with Go’s Tracer enabled and see what happens with all those goroutines.
$ ./bin/rev1 data/indiv18/itcont_1e6.txt 2> rev1.trace
Most common name time: 9.761422905s
$ go tool trace rev1.trace
2019/03/21 22:15:28 Parsing trace...
2019/03/21 22:16:29 Splitting trace...
2019/03/21 22:18:47 Opening browser. Trace viewer is listening on http://127.0.0.1:58572
$
We run a subset of 1 million lines of data of the full dataset to trace what happens in this revision to shorten the runtime a bit. It runs for just under 10 seconds. If we extrapolate that to the full dataset, we would run for 18 x 10s = 180s but it seems over the whole dataset the contention we experience gets a whole lot worse.
We inspect the first 10 seconds and therefore a million lines of data are processed and 3 million messages are sent over the three channels. We can’t display the whole tracing time with the Go Tracer as it has too many data points. The browser that is used to visualise would just blow up with its memory used. The Tracer will provide links of consecutive segements of about 100-300ms depending on the traces density.
What we see in these Tracer logs are two goroutines, one reading lines and starting goroutines and one receiving messages and then a million of line parsing goroutines that get split up into three pieces whenever they send a message to a channel. When we pick one of the ~120ms in the beginning of the trace, we see excactly that. The goroutine G1 issues systemcalls to read the file and then start the line processing goroutine. Then a goroutine called G6 that represents the for-select loop to drain messages from one of these channels and append the data to one of the lists.
Picking a tracer segment from the middle or end of the trace log, we see that the file reading goroutine is not running anymore and G6 is just there to pick up any waiting gorutines receiving their messages (G6 waits in runtime.selectgo()). All CPU cores are saturated with mostly just waiting to get messages from these waiting goroutines. This then sums up to the 12minutes we measured. (For a more detailed description of the Tracer, see Appendix B4)
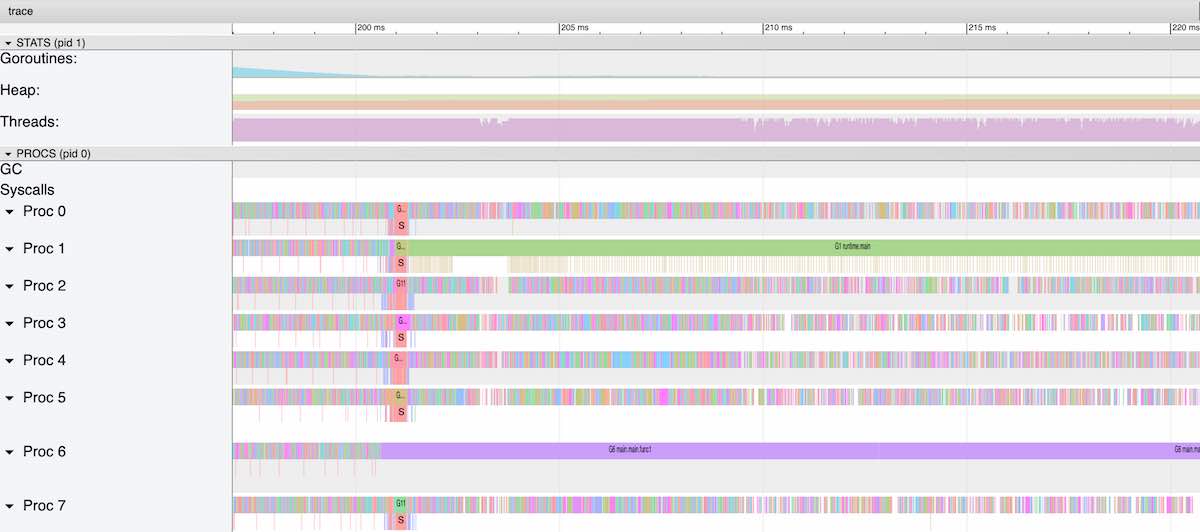
If we are right and the channels have to wait for their receiving end to read the messages, we should also find that goroutines are split up into three pieces most of the time. They split when we send a message to one of the three channels as a concurrently running goroutine with our line parsing because Go is scheduling goroutines at points where it is very likely that a goroutine will wait and an another goroutine could be scheduled to run.
62 go func() {
63 // get all the names
64 split := strings.SplitN(text, "|", 9) // 10.95
65 name := strings.TrimSpace(split[7])
66 namesC <- name
67
68 // extract first names
69 if matches := firstNamePat.FindAllStringSubmatch(name, 1); len(matches) > 0 {
70 firstNamesC <- matches[0][1]
71 } else {
72 wg.Add(-1)
73 }
74
75 // extract dates
76 chars := strings.TrimSpace(split[4])[:6]
77 date := chars[:4] + "-" + chars[4:6]
78 datesC <- date
79 }()
At each point, Go schedules the goroutine if the receiving end is not ready to receive our value. There is a high probability that the receiving end is not ready for our very current value. Other goroutines are doing the same, and the one receiving goroutine G6 has to select from all other waiting goroutines doing the same.
Revision 1 – Conclusion
I think it was a silly idea to kick off a goroutine for every line we process and even sillier to send then three times of that amount messages to three channels over to an another goroutine. But even if silly, its an explanatory example of what not to do. And for this it was worth and educating to see what happens then.
Revision 2 – Channels Reduced
So Go’s concurrency utilities applied to a problem does not help as we learned it quite fast. With Revision2 – readfile2.go – we try to reduce the overhead of communication over the three channels. We introduce a type named entry that combines the name, firstname and donation date into a struct. Also we embedd a reference to a [sync.WaitGroup][go_sync_waitgroup] which helps us to have some kind of bookkeeping of where we are with our concurrent processing of such entries Lines 30-37.
[go_sync_waitgroup]:https://golang.org/pkg/sync/#WaitGroup
Next, we allocate a slice of strings to buffer a chunk of lines and then process them using a goroutine. We try to find a good chunk-size for this and select 64k lines. So instead of starting a new goroutine fo every line, we do that for every 64k lines. A line is then parsed into a entry struct and sent over to a collecting goroutine over 1 channel Lines 55-85.
30 type entry struct {
31 firstName string
32 name string
33 date string
34 wg *sync.WaitGroup
35 }
36 entries := make(chan entry)
37 wg := sync.WaitGroup{}
55 linesChunkLen := 64 * 1024
56 lines := make([]string, 0, 0)
57 for scanner.Scan() {
58 line := scanner.Text()
59 lines = append(lines, line)
60 if len(lines) == linesChunkLen {
61 wg.Add(len(lines))
62 process := lines
63 go func() {
64 for _, text := range process {
65 // get all the names
66 e := entry{wg: &wg}
67 split := strings.SplitN(text, "|", 9)
68 name := strings.TrimSpace(split[7])
69 e.name = name
70
71 // extract first names
72 if matches := firstNamePat.FindAllStringSubmatch(name, 1); len(matches) > 0 {
73 e.firstName = matches[0][1]
74 }
75 // extract dates
76 chars := strings.TrimSpace(split[4])[:6]
77 e.date = chars[:4] + "-" + chars[4:6]
78 entries <- e
79 }
80 }()
81 lines = make([]string, 0, chunkLen)
82 }
83 }
84 wg.Wait()
85 close(entries)
1package main
2
3import (
4 "bufio"
5 "fmt"
6 "log"
7 "os"
8 "regexp"
9 "strings"
10 "sync"
11 "time"
12)
13
14func main() {
15 start := time.Now()
16 file, err := os.Open(os.Args[1])
17 if err != nil {
18 log.Fatal(err)
19 }
20 defer file.Close()
21
22 firstNamePat := regexp.MustCompile(", \\s*([^, ]+)")
23 names := make([]string, 0)
24 firstNames := make([]string, 0)
25 dates := make([]string, 0)
26 commonName := ""
27 commonCount := 0
28 scanner := bufio.NewScanner(file)
29
30 type entry struct {
31 firstName string
32 name string
33 date string
34 wg *sync.WaitGroup
35 }
36 entries := make(chan entry)
37 wg := sync.WaitGroup{}
38
39 go func() {
40 for {
41 select {
42 case entry, ok := <-entries:
43 if ok {
44 if entry.firstName != "" {
45 firstNames = append(firstNames, entry.firstName)
46 }
47 names = append(names, entry.name)
48 dates = append(dates, entry.date)
49 entry.wg.Done()
50 }
51 }
52 }
53 }()
54
55 linesChunkLen := 64 * 1024
56 lines := make([]string, 0, 0)
57 for scanner.Scan() {
58 line := scanner.Text()
59 lines = append(lines, line)
60 if len(lines) == linesChunkLen {
61 wg.Add(len(lines))
62 process := lines
63 go func() {
64 for _, text := range process {
65 // get all the names
66 e := entry{wg: &wg}
67 split := strings.SplitN(text, "|", 9)
68 name := strings.TrimSpace(split[7])
69 e.name = name
70
71 // extract first names
72 if matches := firstNamePat.FindAllStringSubmatch(name, 1); len(matches) > 0 {
73 e.firstName = matches[0][1]
74 }
75 // extract dates
76 chars := strings.TrimSpace(split[4])[:6]
77 e.date = chars[:4] + "-" + chars[4:6]
78 entries <- e
79 }
80 }()
81 lines = make([]string, 0, chunkLen)
82 }
83 }
84 wg.Wait()
85 close(entries)
86
87 // report c2: names at index
88 fmt.Printf("Name: %s at index: %v\n", names[0], 0)
89 fmt.Printf("Name: %s at index: %v\n", names[432], 432)
90 fmt.Printf("Name: %s at index: %v\n", names[43243], 43243)
91 fmt.Printf("Name time: %v\n", time.Since(start))
92
93 // report c1: total number of lines
94 fmt.Printf("Total file line count: %v\n", len(names))
95 fmt.Printf("Line count time: %v\n", time.Since(start))
96
97 // report c3: donation frequency
98 dateMap := make(map[string]int)
99 for _, date := range dates {
100 dateMap[date] += 1
101 }
102 for k, v := range dateMap {
103 fmt.Printf("Donations per month and year: %v and donation count: %v\n", k, v)
104 }
105 fmt.Printf("Donations time: %v\n", time.Since(start))
106
107 /* report c4: most common firstName */
108 nameMap := make(map[string]int)
109 nameCount := 0
110 for _, name := range firstNames {
111 nameCount = nameMap[name] + 1
112 nameMap[name] = nameCount
113 if nameCount > commonCount {
114 commonName = name
115 commonCount = nameCount
116 }
117 }
118 fmt.Printf("The most common first name is: %s and it occurs: %v times.\n", commonName, commonCount)
119 fmt.Printf("Most common name time: %v\n", time.Since(start))
120}
1--- rev1/readfile1.go 2019-03-30 17:23:07.000000000 +0100
2+++ rev2/readfile2.go 2019-03-30 17:24:00.000000000 +0100
3@@ -26,59 +26,63 @@
4 commonName := ""
5 commonCount := 0
6 scanner := bufio.NewScanner(file)
7- namesC := make(chan string)
8- firstNamesC := make(chan string)
9- datesC := make(chan string)
10+
11+ type entry struct {
12+ firstName string
13+ name string
14+ date string
15+ wg *sync.WaitGroup
16+ }
17+ entries := make(chan entry)
18 wg := sync.WaitGroup{}
19
20 go func() {
21 for {
22 select {
23- case n, ok := <-namesC:
24- if ok {
25- names = append(names, n)
26- wg.Done()
27- }
28- case fn, ok := <-firstNamesC:
29- if ok {
30- firstNames = append(firstNames, fn)
31- wg.Done()
32- }
33- case d, ok := <-datesC:
34+ case entry, ok := <-entries:
35 if ok {
36- dates = append(dates, d)
37- wg.Done()
38+ if entry.firstName != "" {
39+ firstNames = append(firstNames, entry.firstName)
40+ }
41+ names = append(names, entry.name)
42+ dates = append(dates, entry.date)
43+ entry.wg.Done()
44 }
45 }
46 }
47 }()
48
49+ chunkLen := 64 * 1024
50+ lines := make([]string, 0, 0)
51 for scanner.Scan() {
52- text := scanner.Text()
53- wg.Add(3)
54- go func() {
55- // get all the names
56- split := strings.SplitN(text, "|", 9)
57- name := strings.TrimSpace(split[7])
58- namesC <- name
59-
60- // extract first names
61- if matches := firstNamePat.FindAllStringSubmatch(name, 1); len(matches) > 0 {
62- firstNamesC <- matches[0][1]
63- } else {
64- wg.Add(-1)
65- }
66-
67- // extract dates
68- chars := strings.TrimSpace(split[4])[:6]
69- date := chars[:4] + "-" + chars[4:6]
70- datesC <- date
71- }()
72+ line := scanner.Text()
73+ lines = append(lines, line)
74+ if len(lines) == chunkLen {
75+ wg.Add(len(lines))
76+ process := lines
77+ go func() {
78+ for _, text := range process {
79+ // get all the names
80+ e := entry{wg: &wg}
81+ split := strings.SplitN(text, "|", 9)
82+ name := strings.TrimSpace(split[7])
83+ e.name = name
84+
85+ // extract first names
86+ if matches := firstNamePat.FindAllStringSubmatch(name, 1); len(matches) > 0 {
87+ e.firstName = matches[0][1]
88+ }
89+ // extract dates
90+ chars := strings.TrimSpace(split[4])[:6]
91+ e.date = chars[:4] + "-" + chars[4:6]
92+ entries <- e
93+ }
94+ }()
95+ lines = make([]string, 0, chunkLen)
96+ }
97 }
98 wg.Wait()
99- close(namesC)
100- close(firstNamesC)
101- close(datesC)
102+ close(entries)
103
104 // report c2: names at index
105 fmt.Printf("Name: %s at index: %v\n", names[0], 0)
Performance
$ go run rev2/readfile2.go itcont.txt
Most common name time: 18.28508803s
$
With 18.2 seconds for this revision, we’re 6.8 seconds below our first revision. Thats a wooping -27% or 1.36x.
The trace log shows what we might expect. A goroutine reads lines of data and hands them over in chunks where they are parsed and for each line an entry of our three data fields are composed and then, entry by entry, sent over a channel to a collecting goroutine. We’re now concurrent, but the CPU cores still not working for us.
Revision 3 – Multiple Entries to Send
With readfile3.go lets reduce the overhead for communication over channels even further and for every 64k chunk of lines, we collect the same amount of entries into a slice and send them over the entries channel entriesC. Our channel is now a channel of a slice of entries Lines 30-83.
30type entry struct {
31 firstName string
32 name string
33 date string
34 wg *sync.WaitGroup
35 }
36 entriesC := make(chan []entry)
37 wg := sync.WaitGroup{}
38 go func() {
39 for {
40 select {
41 case entries, ok := <-entriesC:
42 if ok {
43 for _, entry := range entries {
44 if entry.firstName != "" {
45 firstNames = append(firstNames, entry.firstName)
46 }
47 names = append(names, entry.name)
48 dates = append(dates, entry.date)
49 entry.wg.Done()
50 }
51 }
52 }
53 }
54 }()
55 linesChunkLen := 64 * 1024
56 lines := make([]string, 0, 0)
57 scanner.Scan()
58 for {
59 lines = append(lines, scanner.Text())
60 willScan := scanner.Scan()
61 if len(lines) == linesChunkLen || !willScan {
62 toProcess := lines
63 wg.Add(len(toProcess))
64 go func() {
65 entries := make([]entry, 0, len(toProcess))
66 for _, text := range toProcess {
67 // get all the names
68 e := entry{wg: &wg}
69 split := strings.SplitN(text, "|", 9)
70 name := strings.TrimSpace(split[7])
71 e.name = name
72 // extract first names
73 if matches := firstNamePat.FindAllStringSubmatch(name, 1); len(matches) > 0 {
74 e.firstName = matches[0][1]
75 }
76 // extract dates
77 chars := strings.TrimSpace(split[4])[:6]
78 e.date = chars[:4] + "-" + chars[4:6]
79 entries = append(entries, e)
80 }
81 entriesC <- entries
82 }()
83 lines = make([]string, 0, linesChunkLen)
1package main
2
3import (
4 "bufio"
5 "fmt"
6 "log"
7 "os"
8 "regexp"
9 "strings"
10 "sync"
11 "time"
12)
13
14func main() {
15 start := time.Now()
16 file, err := os.Open(os.Args[1])
17 if err != nil {
18 log.Fatal(err)
19 }
20 defer file.Close()
21
22 firstNamePat := regexp.MustCompile(", \\s*([^, ]+)")
23 names := make([]string, 0)
24 firstNames := make([]string, 0)
25 dates := make([]string, 0)
26 commonName := ""
27 commonCount := 0
28 scanner := bufio.NewScanner(file)
29
30 type entry struct {
31 firstName string
32 name string
33 date string
34 wg *sync.WaitGroup
35 }
36 entriesC := make(chan []entry)
37 wg := sync.WaitGroup{}
38
39 go func() {
40 for {
41 select {
42 case entries, ok := <-entriesC:
43 if ok {
44 for _, entry := range entries {
45 if entry.firstName != "" {
46 firstNames = append(firstNames, entry.firstName)
47 }
48 names = append(names, entry.name)
49 dates = append(dates, entry.date)
50 entry.wg.Done()
51 }
52 }
53 }
54 }
55 }()
56
57 linesChunkLen := 64 * 1024
58 lines := make([]string, 0, 0)
59 scanner.Scan()
60 for {
61 lines = append(lines, scanner.Text())
62 willScan := scanner.Scan()
63 if len(lines) == linesChunkLen || !willScan {
64 toProcess := lines
65 wg.Add(len(toProcess))
66 go func() {
67 entries := make([]entry, 0, len(toProcess))
68 for _, text := range toProcess {
69 // get all the names
70 entry := entry{wg: &wg}
71 split := strings.SplitN(text, "|", 9)
72 name := strings.TrimSpace(split[7])
73 entry.name = name
74
75 // extract first names
76 if matches := firstNamePat.FindAllStringSubmatch(name, 1); len(matches) > 0 {
77 entry.firstName = matches[0][1]
78 }
79 // extract dates
80 chars := strings.TrimSpace(split[4])[:6]
81 entry.date = chars[:4] + "-" + chars[4:6]
82 entries = append(entries, entry)
83 }
84 entriesC <- entries
85 }()
86 lines = make([]string, 0, linesChunkLen)
87 }
88 if !willScan {
89 break
90 }
91 }
92 wg.Wait()
93 close(entriesC)
94
95 // report c2: names at index
96 fmt.Printf("Name: %s at index: %v\n", names[0], 0)
97 fmt.Printf("Name: %s at index: %v\n", names[432], 432)
98 fmt.Printf("Name: %s at index: %v\n", names[43243], 43243)
99 fmt.Printf("Name time: %v\n", time.Since(start))
100
101 // report c1: total number of lines
102 fmt.Printf("Total file line count: %v\n", len(names))
103 fmt.Printf("Line count time: %v\n", time.Since(start))
104
105 // report c3: donation frequency
106 dateMap := make(map[string]int)
107 for _, date := range dates {
108 dateMap[date] += 1
109 }
110 for k, v := range dateMap {
111 fmt.Printf("Donations per month and year: %v and donation count: %v\n", k, v)
112 }
113 fmt.Printf("Donations time: %v\n", time.Since(start))
114
115 // report c4: most common firstName
116 nameMap := make(map[string]int)
117 nameCount := 0 // new count
118 for _, name := range firstNames {
119 nameCount = nameMap[name] + 1
120 nameMap[name] = nameCount
121 if nameCount > commonCount {
122 commonName = name
123 commonCount = nameCount
124 }
125 }
126 fmt.Printf("The most common first name is: %s and it occurs: %v times.\n", commonName, commonCount)
127 fmt.Printf("Most common name time: %v\n", time.Since(start))
128}
1--- rev2/readfile2.go 2019-03-30 19:06:05.000000000 +0100
2+++ rev3/readfile3.go 2019-03-30 19:38:57.000000000 +0100
3@@ -33,20 +33,22 @@
4 date string
5 wg *sync.WaitGroup
6 }
7- entries := make(chan entry)
8+ entriesC := make(chan []entry)
9 wg := sync.WaitGroup{}
10
11 go func() {
12 for {
13 select {
14- case entry, ok := <-entries:
15+ case entries, ok := <-entriesC:
16 if ok {
17- if entry.firstName != "" {
18- firstNames = append(firstNames, entry.firstName)
19+ for _, entry := range entries {
20+ if entry.firstName != "" {
21+ firstNames = append(firstNames, entry.firstName)
22+ }
23+ names = append(names, entry.name)
24+ dates = append(dates, entry.date)
25+ entry.wg.Done()
26 }
27- names = append(names, entry.name)
28- dates = append(dates, entry.date)
29- entry.wg.Done()
30 }
31 }
32 }
33@@ -54,35 +56,41 @@
34
35 linesChunkLen := 64 * 1024
36 lines := make([]string, 0, 0)
37- for scanner.Scan() {
38- line := scanner.Text()
39- lines = append(lines, line)
40- if len(lines) == linesChunkLen {
41- wg.Add(len(lines))
42- process := lines
43+ scanner.Scan()
44+ for {
45+ lines = append(lines, scanner.Text())
46+ willScan := scanner.Scan()
47+ if len(lines) == linesChunkLen || !willScan {
48+ toProcess := lines
49+ wg.Add(len(toProcess))
50 go func() {
51- for _, text := range process {
52+ entries := make([]entry, 0, len(toProcess))
53+ for _, text := range toProcess {
54 // get all the names
55- e := entry{wg: &wg}
56+ entry := entry{wg: &wg}
57 split := strings.SplitN(text, "|", 9)
58 name := strings.TrimSpace(split[7])
59- e.name = name
60+ entry.name = name
61
62 // extract first names
63 if matches := firstNamePat.FindAllStringSubmatch(name, 1); len(matches) > 0 {
64- e.firstName = matches[0][1]
65+ entry.firstName = matches[0][1]
66 }
67 // extract dates
68 chars := strings.TrimSpace(split[4])[:6]
69- e.date = chars[:4] + "-" + chars[4:6]
70- entries <- e
71+ entry.date = chars[:4] + "-" + chars[4:6]
72+ entries = append(entries, entry)
73 }
74+ entriesC <- entries
75 }()
76 lines = make([]string, 0, linesChunkLen)
77 }
78+ if !willScan {
79+ break
80+ }
81 }
82 wg.Wait()
83- close(entries)
84+ close(entriesC)
85
86 // report c2: names at index
87 fmt.Printf("Name: %s at index: %v\n", names[0], 0)
88@@ -106,7 +114,7 @@
89
90 // report c4: most common firstName
91 nameMap := make(map[string]int)
92- nameCount := 0 // new count
93+ nameCount := 0
94 for _, name := range firstNames {
95 nameCount = nameMap[name] + 1
96 nameMap[name] = nameCount
97@@ -117,4 +125,4 @@
98 }
99 fmt.Printf("The most common first name is: %s and it occurs: %v times.\n", commonName, commonCount)
100 fmt.Printf("Most common name time: %v\n", time.Since(start))
101-}
102+}
103\ No newline at end of file
Performance
$ go run ./rev3/readfile3.go
Most common name time: 10.66832747s
$
Here we go: 10.66 seconds. We’re down another 8 seconds or -42%, which is quite a lot. We see less goroutines running in general. The CPU cores are still well used and 6-7 goroutines are constantly Running. Revision 3 is what we planned to do, reading lines and hand them over to process them on a dedicated goroutine. With this plan, we got a reduction of 60% from our port, Revision 0.
Revision 4 – Hang in on a Mutex
In this revision – readfile4.go – we still build up chunks of parsed lines as entries, but we don’t share them over a channel to get them appended to our three lists. Instead we inline the lists appending into our loop and protect this code section with a sync.Mutex. Here we remove one instance of resource contention. Instead of having chunks of entries sent over a channel and get processed on the other end by a collecting goroutine, we wait, through a call to mutex.Lock() until we can enter the section of code to append the parsed entries to the three lists Lines 65-74.
65 mutex.Lock()
66 for _, entry := range entries {
67 if entry.firstName != "" {
68 firstNames = append(firstNames, entry.firstName)
69 }
70 names = append(names, entry.name)
71 dates = append(dates, entry.date)
72 }
73 wg.Add(-len(entries))
74 mutex.Unlock()
1package main
2
3import (
4 "bufio"
5 "fmt"
6 "log"
7 "os"
8 "regexp"
9 "strings"
10 "sync"
11 "time"
12)
13
14func main() {
15 start := time.Now()
16 file, err := os.Open(os.Args[1])
17 if err != nil {
18 log.Fatal(err)
19 }
20 defer file.Close()
21
22 firstNamePat := regexp.MustCompile(", \\s*([^, ]+)")
23 names := make([]string, 0)
24 firstNames := make([]string, 0)
25 dates := make([]string, 0)
26 commonName := ""
27 commonCount := 0
28 scanner := bufio.NewScanner(file)
29
30 type entry struct {
31 firstName string
32 name string
33 date string
34 }
35 mutex := sync.Mutex{}
36 wg := sync.WaitGroup{}
37
38 linesChunkLen := 64 * 1024
39 lines := make([]string, 0, 0)
40 scanner.Scan()
41 for {
42 lines = append(lines, scanner.Text())
43 willScan := scanner.Scan()
44 if len(lines) == linesChunkLen || !willScan {
45 toProcess := lines
46 wg.Add(len(toProcess))
47 go func() {
48 entries := make([]entry, 0, len(toProcess))
49 for _, text := range toProcess {
50 // get all the names
51 entry := entry{}
52 split := strings.SplitN(text, "|", 9)
53 name := strings.TrimSpace(split[7])
54 entry.name = name
55
56 // extract first names
57 if matches := firstNamePat.FindAllStringSubmatch(name, 1); len(matches) > 0 {
58 entry.firstName = matches[0][1]
59 }
60 // extract dates
61 chars := strings.TrimSpace(split[4])[:6]
62 entry.date = chars[:4] + "-" + chars[4:6]
63 entries = append(entries, entry)
64 }
65 mutex.Lock()
66 for _, entry := range entries {
67 if entry.firstName != "" {
68 firstNames = append(firstNames, entry.firstName)
69 }
70 names = append(names, entry.name)
71 dates = append(dates, entry.date)
72 }
73 wg.Add(-len(entries))
74 mutex.Unlock()
75 }()
76 lines = make([]string, 0, linesChunkLen)
77 }
78 if !willScan {
79 break
80 }
81 }
82 wg.Wait()
83
84 // report c2: names at index
85 fmt.Printf("Name: %s at index: %v\n", names[0], 0)
86 fmt.Printf("Name: %s at index: %v\n", names[432], 432)
87 fmt.Printf("Name: %s at index: %v\n", names[43243], 43243)
88 fmt.Printf("Name time: %v\n", time.Since(start))
89
90 // report c1: total number of lines
91 fmt.Printf("Total file line count: %v\n", len(names))
92 fmt.Printf("Line count time: %v\n", time.Since(start))
93
94 // report c3: donation frequency
95 dateMap := make(map[string]int)
96 for _, date := range dates {
97 dateMap[date] += 1
98 }
99 for k, v := range dateMap {
100 fmt.Printf("Donations per month and year: %v and donation count: %v\n", k, v)
101 }
102 fmt.Printf("Donations time: %v\n", time.Since(start))
103
104 // report c4: most common firstName
105 nameMap := make(map[string]int)
106 nameCount := 0
107 for _, name := range firstNames {
108 nameCount = nameMap[name] + 1
109 nameMap[name] = nameCount
110 if nameCount > commonCount {
111 commonName = name
112 commonCount = nameCount
113 }
114 }
115 fmt.Printf("The most common first name is: %s and it occurs: %v times.\n", commonName, commonCount)
116 fmt.Printf("Most common name time: %v\n", time.Since(start))
117}
1--- rev3/readfile3.go 2019-03-30 19:38:57.000000000 +0100
2+++ rev4/readfile4.go 2019-03-30 19:38:28.000000000 +0100
3@@ -31,29 +31,10 @@
4 firstName string
5 name string
6 date string
7- wg *sync.WaitGroup
8 }
9- entriesC := make(chan []entry)
10+ mutex := sync.Mutex{}
11 wg := sync.WaitGroup{}
12
13- go func() {
14- for {
15- select {
16- case entries, ok := <-entriesC:
17- if ok {
18- for _, entry := range entries {
19- if entry.firstName != "" {
20- firstNames = append(firstNames, entry.firstName)
21- }
22- names = append(names, entry.name)
23- dates = append(dates, entry.date)
24- entry.wg.Done()
25- }
26- }
27- }
28- }
29- }()
30-
31 linesChunkLen := 64 * 1024
32 lines := make([]string, 0, 0)
33 scanner.Scan()
34@@ -67,7 +48,7 @@
35 entries := make([]entry, 0, len(toProcess))
36 for _, text := range toProcess {
37 // get all the names
38- entry := entry{wg: &wg}
39+ entry := entry{}
40 split := strings.SplitN(text, "|", 9)
41 name := strings.TrimSpace(split[7])
42 entry.name = name
43@@ -81,7 +62,16 @@
44 entry.date = chars[:4] + "-" + chars[4:6]
45 entries = append(entries, entry)
46 }
47- entriesC <- entries
48+ mutex.Lock()
49+ for _, entry := range entries {
50+ if entry.firstName != "" {
51+ firstNames = append(firstNames, entry.firstName)
52+ }
53+ names = append(names, entry.name)
54+ dates = append(dates, entry.date)
55+ }
56+ wg.Add(-len(entries))
57+ mutex.Unlock()
58 }()
59 lines = make([]string, 0, linesChunkLen)
60 }
61@@ -90,7 +80,6 @@
62 }
63 }
64 wg.Wait()
65- close(entriesC)
66
67 // report c2: names at index
68 fmt.Printf("Name: %s at index: %v\n", names[0], 0)
As we can see here, we don’t need a channel to share our data to get finally be collected. Our goroutine can wait, with its collected data, on a mutex until the mutex is free. Then the goroutine is just parked in memory until it is scheduled to proceed. Go is well prepared for such a scenario as explained in sync/mutex.go. Instead of, that the data is waiting to get drained on a channel and then appended to a list, our processing goroutine is waiting until it can append the parsed data to those lists itself.
Performance
$ go run ./rev4/readfile4.go
Most common name time: 10.31209465s
$
The CPU cores are still well used as we’re having 6 goroutines running at a time. With this revision the compository structure of code by an explicit channel is gone. We didn’t gain much, but we keep this revisions changes for now.
Revision 5 – Inside the Loop
When we inspect the run-times, we can see that different sections take different run times.
Donations per month and year: 2018-08 and donation count: 733865
Donations per month and year: 2018-10 and donation count: 2615902
Donations per month and year: 2017-05 and donation count: 197636
Donations time: : 10.371920253s
The most common first name is: JOHN and it occurs: 475350 times.
Most common name time: 12.296942248s
Here, between donations time and common name time, we take about 2 seconds to range over the firstNames slice and find the most common name. Lets try to bring both of them, the donations frequency table and the commons name counting into our parsing loop. So after we parsed our lines into entries, when appending to the lists, we update the date frequencies and common name counting right inside the loop Lines 68-81. This way, we don’t have to loop over those two maps, we should gain some seconds this way – readfile5.go
68 for _, entry := range entries {
69 if entry.firstName != "" {
70 firstNames = append(firstNames, entry.firstName)
71 nameCount := nameMap[entry.firstName]
72 nameMap[entry.firstName] = nameCount + 1
73 if nameCount+1 > commonCount {
74 commonName = entry.firstName
75 commonCount = nameCount + 1
76 }
77 }
78 names = append(names, entry.name)
79 dates = append(dates, entry.date)
80 dateMap[entry.date]++
81 }
1package main
2
3import (
4 "bufio"
5 "fmt"
6 "log"
7 "os"
8 "regexp"
9 "strings"
10 "sync"
11 "time"
12)
13
14func main() {
15 start := time.Now()
16 file, err := os.Open(os.Args[1])
17 if err != nil {
18 log.Fatal(err)
19 }
20 defer file.Close()
21
22 firstNamePat := regexp.MustCompile(", \\s*([^, ]+)")
23 names := make([]string, 0)
24 firstNames := make([]string, 0)
25 dates := make([]string, 0)
26 commonName := ""
27 commonCount := 0
28 scanner := bufio.NewScanner(file)
29 nameMap := make(map[string]int)
30 dateMap := make(map[string]int)
31
32 type entry struct {
33 firstName string
34 name string
35 date string
36 }
37 mutex := &sync.Mutex{}
38 wg := sync.WaitGroup{}
39
40 linesChunkLen := 64 * 1024
41 lines := make([]string, 0, linesChunkLen)
42 scanner.Scan()
43 for {
44 lines = append(lines, scanner.Text())
45 willScan := scanner.Scan()
46 if len(lines) == linesChunkLen || !willScan {
47 toProcess := lines
48 wg.Add(len(toProcess))
49 go func() {
50 entries := make([]entry, 0, len(toProcess))
51 for _, text := range toProcess {
52 // get all the names
53 entry := entry{}
54 split := strings.SplitN(text, "|", 9)
55 name := strings.TrimSpace(split[7])
56 entry.name = name
57
58 // extract first names
59 if matches := firstNamePat.FindAllStringSubmatch(name, 1); len(matches) > 0 {
60 entry.firstName = matches[0][1]
61 }
62 // extract dates
63 chars := strings.TrimSpace(split[4])[:6]
64 entry.date = chars[:4] + "-" + chars[4:6]
65 entries = append(entries, entry)
66 }
67 mutex.Lock()
68 for _, entry := range entries {
69 if entry.firstName != "" {
70 firstNames = append(firstNames, entry.firstName)
71 nameCount := nameMap[entry.firstName]
72 nameMap[entry.firstName] = nameCount + 1
73 if nameCount+1 > commonCount {
74 commonName = entry.firstName
75 commonCount = nameCount + 1
76 }
77 }
78 names = append(names, entry.name)
79 dates = append(dates, entry.date)
80 dateMap[entry.date]++
81 }
82 wg.Add(-len(entries))
83 mutex.Unlock()
84 }()
85 lines = make([]string, 0, linesChunkLen)
86 }
87 if !willScan {
88 break
89 }
90 }
91 wg.Wait()
92
93 // report c2: names at index
94 fmt.Printf("Name: %s at index: %v\n", names[0], 0)
95 fmt.Printf("Name: %s at index: %v\n", names[432], 432)
96 fmt.Printf("Name: %s at index: %v\n", names[43243], 43243)
97 fmt.Printf("Name time: %v\n", time.Since(start))
98
99 // report c1: total number of lines
100 fmt.Printf("Total file line count: %v\n", len(names))
101 fmt.Printf("Line count time: %v\n", time.Since(start))
102
103 // report c3: donation frequency
104 for k, v := range dateMap {
105 fmt.Printf("Donations per month and year: %v and donation ncount: %v\n", k, v)
106 }
107 fmt.Printf("Donations time: %v\n", time.Since(start))
108
109 // report c4: most common firstName
110 fmt.Printf("The most common first name is: %s and it occurs: %v times.\n", commonName, commonCount)
111 fmt.Printf("Most common name time: %v\n", time.Since(start))
112}
1--- rev4/readfile4.go 2019-03-30 19:38:28.000000000 +0100
2+++ rev5/readfile5.go 2019-03-30 20:12:21.000000000 +0100
3@@ -26,17 +26,19 @@
4 commonName := ""
5 commonCount := 0
6 scanner := bufio.NewScanner(file)
7+ nameMap := make(map[string]int)
8+ dateMap := make(map[string]int)
9
10 type entry struct {
11 firstName string
12 name string
13 date string
14 }
15- mutex := sync.Mutex{}
16+ mutex := &sync.Mutex{}
17 wg := sync.WaitGroup{}
18
19 linesChunkLen := 64 * 1024
20- lines := make([]string, 0, 0)
21+ lines := make([]string, 0, linesChunkLen)
22 scanner.Scan()
23 for {
24 lines = append(lines, scanner.Text())
25@@ -66,9 +68,16 @@
26 for _, entry := range entries {
27 if entry.firstName != "" {
28 firstNames = append(firstNames, entry.firstName)
29+ nameCount := nameMap[entry.firstName]
30+ nameMap[entry.firstName] = nameCount + 1
31+ if nameCount+1 > commonCount {
32+ commonName = entry.firstName
33+ commonCount = nameCount + 1
34+ }
35 }
36 names = append(names, entry.name)
37 dates = append(dates, entry.date)
38+ dateMap[entry.date]++
39 }
40 wg.Add(-len(entries))
41 mutex.Unlock()
42@@ -92,26 +101,12 @@
43 fmt.Printf("Line count time: %v\n", time.Since(start))
44
45 // report c3: donation frequency
46- dateMap := make(map[string]int)
47- for _, date := range dates {
48- dateMap[date] += 1
49- }
50 for k, v := range dateMap {
51 fmt.Printf("Donations per month and year: %v and donation count: %v\n", k, v)
52 }
53 fmt.Printf("Donations time: %v\n", time.Since(start))
54
55 // report c4: most common firstName
56- nameMap := make(map[string]int)
57- nameCount := 0
58- for _, name := range firstNames {
59- nameCount = nameMap[name] + 1
60- nameMap[name] = nameCount
61- if nameCount > commonCount {
62- commonName = name
63- commonCount = nameCount
64- }
65- }
66 fmt.Printf("The most common first name is: %s and it occurs: %v times.\n", commonName, commonCount)
67 fmt.Printf("Most common name time: %v\n", time.Since(start))
68 }
69\ No newline at end of file
Performance
$ go run ./rev5/readfile5.go
Most common name time: 8.781626047s
$
And we get an another 1.5 seconds and break the 10 seconds mark for the first time.
Whats happening here? I suspect that the code section where we append parsed data to our lists, is not fully saturating the time that is available to run this code section in relation to everything thats going on elsewhere. Instead of waste this time during the parsing and then serially take time to loop over the maps and do the calculation of the frequency table and the most common name, we place this code inside the loop.
One might come to think about how well that scales with possible future requirements by what we did in Revision 5. In a future challenge or with changing requirements, it could be that placing this code inside the loop has negative consequences regardig its performance. A reasonable point. But we’re here also to perform and these numbers don’t lie when it comes to quantify performance. I don’t say that I’m a supporter of this in all instances in terms of code quality, but we still have some fun here, right?
Revision 6 – Reuse Allocated Memory
Until now we followed no methodical approach to improve our performance. Some claim (also Marks in his article) to have enough experience to come up with good enough ideas to improve performance of a short enough piece of code. And to be honest, I did the same throughout these iterations; without profiling, I decided to apply a method or tool in terms of language- or library features only on my own or out of curiousity. Brendan Gregg defined this as the Streetligh Anti-Method in his book Systems Performance: Enterprise and the Cloud. To improve performance or the try of it by applying stuff you heard of might work, is exactly that.
Streetlight Anti-Method – This method is actually the absence of a deliberate methodology. The user analyzes performance by choosing observability tools that are familiar, found on the Internet, or just at random to see if anything obvious shows up. This approach is hit or miss and can overlook many types of issues.
– Gregg, B. Systems Performance: Enterprise and the Cloud. Prentice Hall, 2013
So lets use a sync.Pool just out of curiosity of what happens Lines 39-53. In our code we allocate slices of lines and slices of entries where we then collect lines of data and then entries of parsed fields. Allocating these 64k-sized slices over and over again might have a negative effect on our performance, right? With a sync.Pool we can re-use allocated slices and making re-allocation unnecessary. Beside the allocation of the slices itself, whenever we append an element to a slice where its capacity is not sufficient, Go grows these slices by a growing factor of 2 for capacities less than 1024 and by 1.25 above – readfile6.go
Until now we allocated line- and entry-slices with a starting capacity of 0. It might be beneficial to allocate them with the linesChunkLen size to where we will grow for sure during the processing of a 64k chunk of lines Lines 64-102.
39 linesChunkLen := 64 * 1024
40 linesChunkPoolAllocated := int64(0)
41 linesPool := sync.Pool{New: func() interface{} {
42 lines := make([]string, 0, linesChunkLen)
43 atomic.AddInt64(&linesChunkPoolAllocated, 1)
44 return lines
45 }}
46 lines := linesPool.Get().([]string)[:0]
47
48 entriesPoolAllocated := int64(0)
49 entriesPool := sync.Pool{New: func() interface{} {
50 entries := make([]entry, 0, linesChunkLen)
51 atomic.AddInt64(&entriesPoolAllocated, 1)
52 return entries
53 }}
64 go func() {
65 entries := entriesPool.Get().([]entry)[:0]
66 for _, text := range linesToProcess {
67 // get all the names
68 entry := entry{}
69 split := strings.SplitN(text, "|", 9)
70 name := strings.TrimSpace(split[7])
71 entry.name = name
72
73 // extract first names
74 if matches := firstNamePat.FindAllStringSubmatch(name, 1); len(matches) > 0 {
75 entry.firstName = matches[0][1]
76 }
77 // extract dates
78 chars := strings.TrimSpace(split[4])[:6]
79 entry.date = chars[:4] + "-" + chars[4:6]
80 entries = append(entries, entry)
81 }
82 mutex.Lock()
83 for _, entry := range entries {
84 if entry.firstName != "" {
85 firstNames = append(firstNames, entry.firstName)
86 nameCount := nameMap[entry.firstName]
87 nameMap[entry.firstName] = nameCount + 1
88 if nameCount+1 > commonCount {
89 commonName = entry.firstName
90 commonCount = nameCount + 1
91 }
92 }
93 names = append(names, entry.name)
94 dates = append(dates, entry.date)
95 dateMap[entry.date]++
96 }
97 entriesPool.Put(entries)
98 linesPool.Put(linesToProcess)
99 wg.Add(-len(entries))
100 mutex.Unlock()
101 }()
102 lines = linesPool.Get().([]string)[:0]
1package main
2
3import (
4 "bufio"
5 "fmt"
6 "log"
7 "os"
8 "regexp"
9 "strings"
10 "sync"
11 "sync/atomic"
12 "time"
13)
14
15func main() {
16 start := time.Now()
17 file, err := os.Open(os.Args[1])
18 if err != nil {
19 log.Fatal(err)
20 }
21 defer file.Close()
22
23 firstNamePat := regexp.MustCompile(", \\s*([^, ]+)")
24 names := make([]string, 0)
25 firstNames := make([]string, 0)
26 dates := make([]string, 0)
27 commonName := ""
28 commonCount := 0
29 scanner := bufio.NewScanner(file)
30 nameMap := make(map[string]int)
31 dateMap := make(map[string]int)
32
33 type entry struct {
34 firstName string
35 name string
36 date string
37 }
38
39 linesChunkLen := 64 * 1024
40 linesChunkPoolAllocated := int64(0)
41 linesPool := sync.Pool{New: func() interface{} {
42 lines := make([]string, 0, linesChunkLen)
43 atomic.AddInt64(&linesChunkPoolAllocated, 1)
44 return lines
45 }}
46 lines := linesPool.Get().([]string)[:0]
47
48 entriesPoolAllocated := int64(0)
49 entriesPool := sync.Pool{New: func() interface{} {
50 entries := make([]entry, 0, linesChunkLen)
51 atomic.AddInt64(&entriesPoolAllocated, 1)
52 return entries
53 }}
54 mutex := &sync.Mutex{}
55 wg := sync.WaitGroup{}
56
57 scanner.Scan()
58 for {
59 lines = append(lines, scanner.Text())
60 willScan := scanner.Scan()
61 if len(lines) == linesChunkLen || !willScan {
62 linesToProcess := lines
63 wg.Add(len(linesToProcess))
64 go func() {
65 entries := entriesPool.Get().([]entry)[:0]
66 for _, text := range linesToProcess {
67 // get all the names
68 entry := entry{}
69 split := strings.SplitN(text, "|", 9)
70 name := strings.TrimSpace(split[7])
71 entry.name = name
72
73 // extract first names
74 if matches := firstNamePat.FindAllStringSubmatch(name, 1); len(matches) > 0 {
75 entry.firstName = matches[0][1]
76 }
77 // extract dates
78 chars := strings.TrimSpace(split[4])[:6]
79 entry.date = chars[:4] + "-" + chars[4:6]
80 entries = append(entries, entry)
81 }
82 mutex.Lock()
83 for _, entry := range entries {
84 if entry.firstName != "" {
85 firstNames = append(firstNames, entry.firstName)
86 nameCount := nameMap[entry.firstName]
87 nameMap[entry.firstName] = nameCount + 1
88 if nameCount+1 > commonCount {
89 commonName = entry.firstName
90 commonCount = nameCount + 1
91 }
92 }
93 names = append(names, entry.name)
94 dates = append(dates, entry.date)
95 dateMap[entry.date]++
96 }
97 entriesPool.Put(entries)
98 linesPool.Put(linesToProcess)
99 wg.Add(-len(entries))
100 mutex.Unlock()
101 }()
102 lines = linesPool.Get().([]string)[:0]
103 }
104 if !willScan {
105 break
106 }
107 }
108 wg.Wait()
109
110 // report c2: names at index
111 fmt.Printf("Name: %s at index: %v\n", names[0], 0)
112 fmt.Printf("Name: %s at index: %v\n", names[432], 432)
113 fmt.Printf("Name: %s at index: %v\n", names[43243], 43243)
114 fmt.Printf("Name time: %v\n", time.Since(start))
115
116 // report c1: total number of lines
117 fmt.Printf("Total file line count: %v\n", len(names))
118 fmt.Printf("Line count time: %v\n", time.Since(start))
119
120 // report c3: donation frequency
121 for k, v := range dateMap {
122 fmt.Printf("Donations per month and year: %v and donation count: %v\n", k, v)
123 }
124 fmt.Printf("Donations time: %v\n", time.Since(start))
125
126 // report c4: most common firstName
127 fmt.Printf("The most common first name is: %s and it occurs: %v times.\n", commonName, commonCount)
128 fmt.Printf("Most common name time: %v\n", time.Since(start))
129}
1--- rev5/readfile5.go 2019-03-31 15:30:24.000000000 +0200
2+++ rev6/readfile6.go 2019-03-31 15:29:30.000000000 +0200
3@@ -8,6 +8,7 @@
4 "regexp"
5 "strings"
6 "sync"
7+ "sync/atomic"
8 "time"
9 )
10
11@@ -34,21 +35,35 @@
12 name string
13 date string
14 }
15+
16+ linesChunkLen := 64 * 1024
17+ linesChunkPoolAllocated := int64(0)
18+ linesPool := sync.Pool{New: func() interface{} {
19+ lines := make([]string, 0, linesChunkLen)
20+ atomic.AddInt64(&linesChunkPoolAllocated, 1)
21+ return lines
22+ }}
23+ lines := linesPool.Get().([]string)[:0]
24+
25+ entriesPoolAllocated := int64(0)
26+ entriesPool := sync.Pool{New: func() interface{} {
27+ entries := make([]entry, 0, linesChunkLen)
28+ atomic.AddInt64(&entriesPoolAllocated, 1)
29+ return entries
30+ }}
31 mutex := &sync.Mutex{}
32 wg := sync.WaitGroup{}
33
34- linesChunkLen := 64 * 1024
35- lines := make([]string, 0, linesChunkLen)
36 scanner.Scan()
37 for {
38 lines = append(lines, scanner.Text())
39 willScan := scanner.Scan()
40 if len(lines) == linesChunkLen || !willScan {
41- toProcess := lines
42- wg.Add(len(toProcess))
43+ linesToProcess := lines
44+ wg.Add(len(linesToProcess))
45 go func() {
46- entries := make([]entry, 0, len(toProcess))
47- for _, text := range toProcess {
48+ entries := entriesPool.Get().([]entry)[:0]
49+ for _, text := range linesToProcess {
50 // get all the names
51 entry := entry{}
52 split := strings.SplitN(text, "|", 9)
53@@ -79,10 +94,12 @@
54 dates = append(dates, entry.date)
55 dateMap[entry.date]++
56 }
57+ entriesPool.Put(entries)
58+ linesPool.Put(linesToProcess)
59 wg.Add(-len(entries))
60 mutex.Unlock()
61 }()
62- lines = make([]string, 0, linesChunkLen)
63+ lines = linesPool.Get().([]string)[:0]
64 }
65 if !willScan {
66 break
Performance
$ go run ./rev6/readfile6.go
Most common name time: 9.235948927s
$
There seems to be no immediate benefit using a sync.Pool to reuse previously allocated slices. Comparing memory allocation TotalAlloc for Revision 5 and 6, we can see a reduction of 1.1GiB less memory allocated during its runtime.
rev5: Alloc = 7072 MiB TotalAlloc = 17216 MiB Sys = 8007 MiB NumGC = 22
rev6: Alloc = 5155 MiB TotalAlloc = 16125 MiB Sys = 7679 MiB NumGC = 27
So there is a benefit, but we don’t measure it in terms of runtime performance. We even loose 0.5 seconds in runtime for the fastest measured time. But if we look closer, the average runtime of revision 5 and revision 6 are very similar
# Min Avg SD TotalAlloc
rev5 8.781626047 9.765141717 0.425628359 17216
rev6 9.235948927 9.651679988 0.421454038 16125
We keep this optimisation to the next round.
Revision 7: Regexp Usage
readfile7.go – Regexp engine implementations are precious machines. Some say Go’s regexp implementaion is not the fastest and indeed having seen Go’s performance in the field vs. Java like in this benchmarksgame where Go’s is about 3x slower than Java supports this opinion.
So lets have a look at our regexp, they are always interesting. I’m not an expert in the matter but lets try to improve here a bit.
We used
// FindAllStringSubmatch is the 'All' version of FindStringSubmatch; it
// returns a slice of all successive matches of the expression, as defined by
// the 'All' description in the package comment.
// A return value of nil indicates no match.
func (re *Regexp) FindAllStringSubmatch(s string, n int) [][]string
which seems to be a bad choice of what we actually need. What we’re looking for is to get the first word after a lastname separated by a comma and a whitespace.
"PEREZ, JOHN A"
"DEEHAN, WILLIAM N"
"WATJEN, THOMAS R."
"SABOURIN, JAMES"
Here we’re looking for JOHN, WILLIAM, THOMAS and JAMES. We also have a capturing group in the regexp which brings a performance penalty generally.
Typically, non-capturing groups perform better than capturing groups, because they require less allocation of memory, and do not make a copy of the group match
StackOverflow 33243292
1--- rev6/readfile6.go 2019-03-31 17:20:27.000000000 +0200
2+++ rev7/readfile7.go 2019-03-31 17:25:05.000000000 +0200
3@@ -20,7 +20,7 @@
4 }
5 defer file.Close()
6
7- firstNamePat := regexp.MustCompile(", \\s*([^, ]+)")
8+ firstNamePat := regexp.MustCompile(", \\s*[^, ]+")
9 names := make([]string, 0)
10 firstNames := make([]string, 0)
11 dates := make([]string, 0)
12@@ -71,8 +71,8 @@
13 entry.name = name
14
15 // extract first names
16- if matches := firstNamePat.FindAllStringSubmatch(name, 1); len(matches) > 0 {
17- entry.firstName = matches[0][1]
18+ if matched := firstNamePat.FindString(name); matched != "" {
19+ entry.firstName = matched[2:]
20 }
21 // extract dates
22 chars := strings.TrimSpace(split[4])[:6]
1package main
2
3import (
4 "bufio"
5 "fmt"
6 "log"
7 "os"
8 "regexp"
9 "strings"
10 "sync"
11 "sync/atomic"
12 "time"
13)
14
15func main() {
16 start := time.Now()
17 file, err := os.Open(os.Args[1])
18 if err != nil {
19 log.Fatal(err)
20 }
21 defer file.Close()
22
23 firstNamePat := regexp.MustCompile(", \\s*[^, ]+")
24 names := make([]string, 0, 0)
25 firstNames := make([]string, 0, 0)
26 dates := make([]string, 0, 0)
27 commonName := ""
28 commonCount := 0
29 scanner := bufio.NewScanner(file)
30 nameMap := make(map[string]int)
31 dateMap := make(map[string]int)
32
33 type entry struct {
34 firstName string
35 name string
36 date string
37 }
38
39 linesChunkLen := 64 * 1024
40 linesChunkPoolAllocated := int64(0)
41 linesPool := sync.Pool{New: func() interface{} {
42 lines := make([]string, 0, linesChunkLen)
43 atomic.AddInt64(&linesChunkPoolAllocated, 1)
44 return lines
45 }}
46 lines := linesPool.Get().([]string)[:0]
47
48 entriesPoolAllocated := int64(0)
49 entriesPool := sync.Pool{New: func() interface{} {
50 entries := make([]entry, 0, linesChunkLen)
51 atomic.AddInt64(&entriesPoolAllocated, 1)
52 return entries
53 }}
54 mutex := &sync.Mutex{}
55 wg := sync.WaitGroup{}
56
57 scanner.Scan()
58 for {
59 lines = append(lines, scanner.Text())
60 willScan := scanner.Scan()
61 if len(lines) == linesChunkLen || !willScan {
62 linesToProcess := lines
63 wg.Add(len(linesToProcess))
64 go func() {
65 entries := entriesPool.Get().([]entry)[:0]
66 for _, text := range linesToProcess {
67 // get all the names
68 entry := entry{}
69 split := strings.SplitN(text, "|", 9)
70 name := strings.TrimSpace(split[7])
71 entry.name = name
72
73 // extract first names
74 if matched := firstNamePat.FindString(name); matched != "" {
75 entry.firstName = matched[2:]
76 }
77 // extract dates
78 chars := strings.TrimSpace(split[4])[:6]
79 entry.date = chars[:4] + "-" + chars[4:6]
80 entries = append(entries, entry)
81 }
82 mutex.Lock()
83 for _, entry := range entries {
84 if entry.firstName != "" {
85 firstNames = append(firstNames, entry.firstName)
86 nameCount := nameMap[entry.firstName]
87 nameMap[entry.firstName] = nameCount + 1
88 if nameCount+1 > commonCount {
89 commonName = entry.firstName
90 commonCount = nameCount + 1
91 }
92 }
93 names = append(names, entry.name)
94 dates = append(dates, entry.date)
95 dateMap[entry.date]++
96 }
97 entriesPool.Put(entries)
98 linesPool.Put(linesToProcess)
99 mutex.Unlock()
100 wg.Add(-len(entries))
101 }()
102 lines = linesPool.Get().([]string)[:0]
103 }
104 if !willScan {
105 break
106 }
107 }
108 wg.Wait()
109
110 // report c2: names at index
111 fmt.Printf("Name: %s at index: %v\n", names[0], 0)
112 fmt.Printf("Name: %s at index: %v\n", names[432], 432)
113 fmt.Printf("Name: %s at index: %v\n", names[43243], 43243)
114 fmt.Printf("Name time: %v\n", time.Since(start))
115
116 // report c1: total number of lines
117 fmt.Printf("Total file line count: %v\n", len(names))
118 fmt.Printf("Line count time: %v\n", time.Since(start))
119
120 // report c3: donation frequency
121 for k, v := range dateMap {
122 fmt.Printf("Donations per month and year: %v and donation count: %v\n", k, v)
123 }
124 fmt.Printf("Donations time: %v\n", time.Since(start))
125
126 // report c4: most common firstName
127 fmt.Printf("The most common first name is: %s and it occurs: %v times.\n", commonName, commonCount)
128 fmt.Printf("Most common name time: %v\n", time.Since(start))
129}
We don’t need the capturing group as we don’t have to reference to the found group later. So lets get rid of them and also use the simpler regexp.FindString()
// FindString returns a string holding the text of the leftmost match in s of the regular
// expression. If there is no match, the return value is an empty string,
// but it will also be empty if the regular expression successfully matches
// an empty string. Use FindStringIndex or FindStringSubmatch if it is
// necessary to distinguish these cases.
func (re *Regexp) FindString(s string) string
Performance
$ go run ./rev7/readfile7.go
Most common name time: 8.155115627s
$
With the simpler regexp we are down another second.
Revision 8: No Regexp
Next, we eliminate our regular expression. Splitting a string by a comma and then find the first word could not be that complicated. Lets do it manually – readfile8.go.
1--- rev7/readfile7.go 2019-03-31 17:25:05.000000000 +0200
2+++ rev8/readfile8.go 2019-03-31 17:32:46.000000000 +0200
3@@ -5,7 +5,6 @@
4 "fmt"
5 "log"
6 "os"
7- "regexp"
8 "strings"
9 "sync"
10 "sync/atomic"
11@@ -20,7 +19,6 @@
12 }
13 defer file.Close()
14
15- firstNamePat := regexp.MustCompile(", \\s*[^, ]+")
16 names := make([]string, 0)
17 firstNames := make([]string, 0)
18 dates := make([]string, 0)
19@@ -71,8 +69,16 @@
20 entry.name = name
21
22 // extract first names
23- if matched := firstNamePat.FindString(name); matched != "" {
24- entry.firstName = matched[2:]
25+ if name != "" {
26+ startOfName := strings.Index(name, ", ") + 2
27+ if endOfName := strings.Index(name[startOfName:], " "); endOfName < 0 {
28+ entry.firstName = name[startOfName:]
29+ } else {
30+ entry.firstName = name[startOfName : startOfName+endOfName]
31+ }
32+ if strings.HasSuffix(entry.firstName, ",") {
33+ entry.firstName = strings.Replace(entry.firstName, ",", "", -1)
34+ }
35 }
36 // extract dates
37 chars := strings.TrimSpace(split[4])[:6]
1package main
2
3import (
4 "bufio"
5 "fmt"
6 "log"
7 "os"
8 "strings"
9 "sync"
10 "sync/atomic"
11 "time"
12)
13
14func main() {
15 start := time.Now()
16 file, err := os.Open(os.Args[1])
17 if err != nil {
18 log.Fatal(err)
19 }
20 defer file.Close()
21
22 names := make([]string, 0)
23 firstNames := make([]string, 0)
24 dates := make([]string, 0)
25 commonName := ""
26 commonCount := 0
27 scanner := bufio.NewScanner(file)
28 nameMap := make(map[string]int)
29 dateMap := make(map[string]int)
30
31 type entry struct {
32 firstName string
33 name string
34 date string
35 }
36
37 linesChunkLen := 64 * 1024
38 linesChunkPoolAllocated := int64(0)
39 linesPool := sync.Pool{New: func() interface{} {
40 lines := make([]string, 0, linesChunkLen)
41 atomic.AddInt64(&linesChunkPoolAllocated, 1)
42 return lines
43 }}
44 lines := linesPool.Get().([]string)[:0]
45
46 entriesPoolAllocated := int64(0)
47 entriesPool := sync.Pool{New: func() interface{} {
48 entries := make([]entry, 0, linesChunkLen)
49 atomic.AddInt64(&entriesPoolAllocated, 1)
50 return entries
51 }}
52 mutex := &sync.Mutex{}
53 wg := sync.WaitGroup{}
54
55 scanner.Scan()
56 for {
57 lines = append(lines, scanner.Text())
58 willScan := scanner.Scan()
59 if len(lines) == linesChunkLen || !willScan {
60 linesToProcess := lines
61 wg.Add(len(linesToProcess))
62 go func() {
63 entries := entriesPool.Get().([]entry)[:0]
64 for _, text := range linesToProcess {
65 // get all the names
66 entry := entry{}
67 split := strings.SplitN(text, "|", 9)
68 name := strings.TrimSpace(split[7])
69 entry.name = name
70
71 // extract first names
72 if name != "" {
73 startOfName := strings.Index(name, ", ") + 2
74 if endOfName := strings.Index(name[startOfName:], " "); endOfName < 0 {
75 entry.firstName = name[startOfName:]
76 } else {
77 entry.firstName = name[startOfName : startOfName+endOfName]
78 }
79 if strings.HasSuffix(entry.firstName, ",") {
80 entry.firstName = strings.Replace(entry.firstName, ",", "", -1)
81 }
82 }
83 // extract dates
84 chars := strings.TrimSpace(split[4])[:6]
85 entry.date = chars[:4] + "-" + chars[4:6]
86 entries = append(entries, entry)
87 }
88 mutex.Lock()
89 for _, entry := range entries {
90 if entry.firstName != "" {
91 firstNames = append(firstNames, entry.firstName)
92 nameCount := nameMap[entry.firstName]
93 nameMap[entry.firstName] = nameCount + 1
94 if nameCount+1 > commonCount {
95 commonName = entry.firstName
96 commonCount = nameCount + 1
97 }
98 }
99 names = append(names, entry.name)
100 dates = append(dates, entry.date)
101 dateMap[entry.date]++
102 }
103 entriesPool.Put(entries)
104 linesPool.Put(linesToProcess)
105 wg.Add(-len(entries))
106 mutex.Unlock()
107 }()
108 lines = linesPool.Get().([]string)[:0]
109 }
110 if !willScan {
111 break
112 }
113 }
114 wg.Wait()
115
116 // report c2: names at index
117 fmt.Printf("Name: %s at index: %v\n", names[0], 0)
118 fmt.Printf("Name: %s at index: %v\n", names[432], 432)
119 fmt.Printf("Name: %s at index: %v\n", names[43243], 43243)
120 fmt.Printf("Name time: %v\n", time.Since(start))
121
122 // report c1: total number of lines
123 fmt.Printf("Total file line count: %v\n", len(names))
124 fmt.Printf("Line count time: %v\n", time.Since(start))
125
126 // report c3: donation frequency
127 for k, v := range dateMap {
128 fmt.Printf("Donations per month and year: %v and donation ncount: %v\n", k, v)
129 }
130 fmt.Printf("Donations time: %v\n", time.Since(start))
131
132 // report c4: most common firstName
133 fmt.Printf("The most common first name is: %s and it occurs: %v times.\n", commonName, commonCount)
134 fmt.Printf("Most common name time: %v\n", time.Since(start))
135}
Performance
$ go run ./rev8/readfile8.go
Most common name time: 6.644675587s
$
Another 1.5 seconds down. Thats awesome, isn’t it?
To peel off one second for the processing of those 18.2 million lines of data, we have to save 55ns for every line. Since we are down to a few seconds runtime even these small improvements pay off. In this case we improved by over 20%.
Revision 9 – Reduce the Garbage
When we look about how much memory our program allocates during its runtime we are down to 11.2GiB now. Thats 3.4 times the size of the file we read through. For sure we have to read at least every byte of our file but we allocate over three times of that memory. Beside the allocation that needs the memory management of the Go runtime involved it also means that Go’s Garbage Collector has to clean up memory that is allocated temporarily and not part of the results lists.
rev8: Alloc = 5788 MiB TotalAlloc = 11217 MiB Sys = 7116 MiB NumGC = 18
With the next step – readfile9.go – we try to reduce the allocate memory or not even allocate memory where it hasn’t to be allocated at all. First, we get rid of our names list; we report the requested indexes right in the loop. We also parse the donations date not as a string, and most important, we don’t slice and combine it to a dash separated year-month string. Instead we parse the given year and month part of the string as an integer. That fits well into our requirements. We can, later still reformat the few dozens or so dates into a format that is better suited to read. The challenge does not require a specific format, so we can leave them right in this more efficient format.
1package main
2
3import (
4 "bufio"
5 "fmt"
6 "log"
7 "os"
8 "strconv"
9 "strings"
10 "sync"
11 "sync/atomic"
12 "time"
13)
14
15func main() {
16 start := time.Now()
17 file, err := os.Open(os.Args[1])
18 if err != nil {
19 log.Fatal(err)
20 }
21 defer file.Close()
22
23 commonName := ""
24 commonCount := 0
25 scanner := bufio.NewScanner(file)
26 nameMap := make(map[string]int)
27 dateMap := make(map[int]int)
28
29 namesCounted := false
30 namesCount := 0
31 fileLineCount := int64(0)
32
33 type entry struct {
34 firstName string
35 name string
36 date int
37 }
38
39 linesChunkLen := 64 * 1024
40 linesChunkPoolAllocated := int64(0)
41 linesPool := sync.Pool{New: func() interface{} {
42 lines := make([]string, 0, linesChunkLen)
43 atomic.AddInt64(&linesChunkPoolAllocated, 1)
44 return lines
45 }}
46 lines := linesPool.Get().([]string)[:0]
47
48 entriesPoolAllocated := int64(0)
49 entriesPool := sync.Pool{New: func() interface{} {
50 entries := make([]entry, 0, linesChunkLen)
51 atomic.AddInt64(&entriesPoolAllocated, 1)
52 return entries
53 }}
54 mutex := &sync.Mutex{}
55 wg := sync.WaitGroup{}
56
57 scanner.Scan()
58 for {
59 lines = append(lines, scanner.Text())
60 willScan := scanner.Scan()
61 if len(lines) == linesChunkLen || !willScan {
62 linesToProcess := lines
63 wg.Add(len(linesToProcess))
64 go func() {
65 atomic.AddInt64(&fileLineCount, int64(len(linesToProcess)))
66 entries := entriesPool.Get().([]entry)[:0]
67 for _, text := range linesToProcess {
68 // get all the names
69 entry := entry{}
70 split := strings.SplitN(text, "|", 9)
71 entry.name = strings.TrimSpace(split[7])
72
73 // extract first names
74 if entry.name != "" {
75 startOfName := strings.Index(entry.name, ", ") + 2
76 if endOfName := strings.Index(entry.name[startOfName:], " "); endOfName < 0 {
77 entry.firstName = entry.name[startOfName:]
78 } else {
79 entry.firstName = entry.name[startOfName : startOfName+endOfName]
80 }
81 if cs := strings.Index(entry.firstName, ","); cs > 0 {
82 entry.firstName = entry.firstName[:cs]
83 }
84 }
85 // extract dates
86 entry.date, _ = strconv.Atoi(split[4][:6])
87 entries = append(entries, entry)
88 }
89 linesPool.Put(linesToProcess)
90 mutex.Lock()
91 for _, entry := range entries {
92 if len(entry.firstName) != 0 {
93 nameCount := nameMap[entry.firstName] + 1
94 nameMap[entry.firstName] = nameCount
95 if nameCount > commonCount {
96 commonCount = nameCount
97 commonName = entry.firstName
98 }
99 }
100 if namesCounted == false {
101 if namesCount == 0 {
102 fmt.Printf("Name: %s at index: %v\n", entry.name, 0)
103 } else if namesCount == 432 {
104 fmt.Printf("Name: %s at index: %v\n", entry.name, 432)
105 } else if namesCount == 43243 {
106 fmt.Printf("Name: %s at index: %v\n", entry.name, 43243)
107 namesCounted = true
108 }
109 namesCount++
110 }
111 dateMap[entry.date]++
112 }
113 mutex.Unlock()
114 entriesPool.Put(entries)
115 wg.Add(-len(entries))
116 }()
117 lines = linesPool.Get().([]string)[:0]
118 }
119 if !willScan {
120 break
121 }
122 }
123 wg.Wait()
124
125 // report c2: names at index
126 fmt.Printf("Name time: %v\n", time.Since(start))
127
128 // report c1: total number of lines
129 fmt.Printf("Total file line count: %v\n", fileLineCount)
130 fmt.Printf("Line count time: %v\n", time.Since(start))
131
132 // report c3: donation frequency
133 for k, v := range dateMap {
134 fmt.Printf("Donations per month and year: %v and donation ncount: %v\n", k, v)
135 }
136 fmt.Printf("Donations time: %v\n", time.Since(start))
137
138 // report c4: most common firstName
139 fmt.Printf("The most common first name is: %s and it occurs: %v times.\n", commonName, commonCount)
140 fmt.Printf("Most common name time: %v\n", time.Since(start))
141}
1--- rev8/readfile8.go 2019-03-31 17:32:46.000000000 +0200
2+++ rev9/readfile9.go 2019-03-31 18:58:16.000000000 +0200
3@@ -5,6 +5,7 @@
4 "fmt"
5 "log"
6 "os"
7+ "strconv"
8 "strings"
9 "sync"
10 "sync/atomic"
11@@ -19,19 +20,20 @@
12 }
13 defer file.Close()
14
15- names := make([]string, 0)
16- firstNames := make([]string, 0)
17- dates := make([]string, 0)
18 commonName := ""
19 commonCount := 0
20 scanner := bufio.NewScanner(file)
21 nameMap := make(map[string]int)
22- dateMap := make(map[string]int)
23+ dateMap := make(map[int]int)
24+
25+ namesCounted := false
26+ namesCount := 0
27+ fileLineCount := int64(0)
28
29 type entry struct {
30 firstName string
31 name string
32- date string
33+ date int
34 }
35
36 linesChunkLen := 64 * 1024
37@@ -60,50 +62,57 @@
38 linesToProcess := lines
39 wg.Add(len(linesToProcess))
40 go func() {
41+ atomic.AddInt64(&fileLineCount, int64(len(linesToProcess)))
42 entries := entriesPool.Get().([]entry)[:0]
43 for _, text := range linesToProcess {
44 // get all the names
45 entry := entry{}
46 split := strings.SplitN(text, "|", 9)
47- name := strings.TrimSpace(split[7])
48- entry.name = name
49+ entry.name = strings.TrimSpace(split[7])
50
51 // extract first names
52- if name != "" {
53- startOfName := strings.Index(name, ", ") + 2
54- if endOfName := strings.Index(name[startOfName:], " "); endOfName < 0 {
55- entry.firstName = name[startOfName:]
56+ if entry.name != "" {
57+ startOfName := strings.Index(entry.name, ", ") + 2
58+ if endOfName := strings.Index(entry.name[startOfName:], " "); endOfName < 0 {
59+ entry.firstName = entry.name[startOfName:]
60 } else {
61- entry.firstName = name[startOfName : startOfName+endOfName]
62+ entry.firstName = entry.name[startOfName : startOfName+endOfName]
63 }
64- if strings.HasSuffix(entry.firstName, ",") {
65- entry.firstName = strings.Replace(entry.firstName, ",", "", -1)
66+ if cs := strings.Index(entry.firstName, ","); cs > 0 {
67+ entry.firstName = entry.firstName[:cs]
68 }
69 }
70 // extract dates
71- chars := strings.TrimSpace(split[4])[:6]
72- entry.date = chars[:4] + "-" + chars[4:6]
73+ entry.date, _ = strconv.Atoi(split[4][:6])
74 entries = append(entries, entry)
75 }
76+ linesPool.Put(linesToProcess)
77 mutex.Lock()
78 for _, entry := range entries {
79- if entry.firstName != "" {
80- firstNames = append(firstNames, entry.firstName)
81- nameCount := nameMap[entry.firstName]
82- nameMap[entry.firstName] = nameCount + 1
83- if nameCount+1 > commonCount {
84+ if len(entry.firstName) != 0 {
85+ nameCount := nameMap[entry.firstName] + 1
86+ nameMap[entry.firstName] = nameCount
87+ if nameCount > commonCount {
88+ commonCount = nameCount
89 commonName = entry.firstName
90- commonCount = nameCount + 1
91 }
92 }
93- names = append(names, entry.name)
94- dates = append(dates, entry.date)
95+ if namesCounted == false {
96+ if namesCount == 0 {
97+ fmt.Printf("Name: %s at index: %v\n", entry.name, 0)
98+ } else if namesCount == 432 {
99+ fmt.Printf("Name: %s at index: %v\n", entry.name, 432)
100+ } else if namesCount == 43243 {
101+ fmt.Printf("Name: %s at index: %v\n", entry.name, 43243)
102+ namesCounted = true
103+ }
104+ namesCount++
105+ }
106 dateMap[entry.date]++
107 }
108+ mutex.Unlock()
109 entriesPool.Put(entries)
110- linesPool.Put(linesToProcess)
111 wg.Add(-len(entries))
112- mutex.Unlock()
113 }()
114 lines = linesPool.Get().([]string)[:0]
115 }
116@@ -114,13 +123,10 @@
117 wg.Wait()
118
119 // report c2: names at index
120- fmt.Printf("Name: %s at index: %v\n", names[0], 0)
121- fmt.Printf("Name: %s at index: %v\n", names[432], 432)
122- fmt.Printf("Name: %s at index: %v\n", names[43243], 43243)
123 fmt.Printf("Name time: %v\n", time.Since(start))
124
125 // report c1: total number of lines
126- fmt.Printf("Total file line count: %v\n", len(names))
127+ fmt.Printf("Total file line count: %v\n", fileLineCount)
128 fmt.Printf("Line count time: %v\n", time.Since(start))
129
130 // report c3: donation frequency
To be honest, our little small 81 lines Go program of revision 0 has mutated into a little monster of 141 lines of code. But lets measure its performance now.
Performance
$ go run ./rev9/readfile9.go
Most common name time: 3.880034076s
$
With that last changes we are below 4 seconds. That’s over 20 seconds less than where we started and over 80 seconds less than the initial solution. What have we done 80 seconds long?
With this revision we’re able to process 4.7 million lines per second. The first revision did 0.73 million lines and the initial original solution to the challenge less than a third of that, 0.217 million lines/second.
rev9: Alloc = 81 MiB TotalAlloc = 6590 MiB Sys = 205 MiB NumGC = 129
When we look at memory allocation we now allocate over 10GiB less memory over its runtime and we are also at half of the previous revision. We also see that the GC is running 129 times vs. the ~20-30 times of all other revisions. Third, heap allocation is constantly at about 120MiB where the OS systems memory is only at 205MiB (see Appendix B2). At the end, Revision 9 had only 81MiB allocated on the heap.
With these memory metrics we can conclude that runtime is also a function of the memory allocation and its management by the garbage collector. When we ran the benchmarking runs for Revision 0 to 9, we can see that Revision 9 also has the smallest variance in runtime with a standard deviation of only 0.07 and therefore a very conistent and stable runtime.
From Revision 0 to 9 – Results
To find the maximum performance, I ran each revision 20x times on my Laptop. I uninstalled my AntiVirus Scanner (Sophos) as he influenced the results significantly. I also turned off background services to get consistent results. MacOS’s Spotlight (Indexer) and my Backup-Daemon (Arq) but also Dropbox where turned off.
The following table shows for each relevant revision (we ommited rev1 for obivious reasons)
- Min, Avg and Standard Deviation/SD of its runtime.
- TotalAlloc is cumulative bytes allocated for heap objects.
- Alloc is bytes of allocated heap objects.
- SD the standard deviation (S)
- NumGC is the number of completed GC cycles.
- LPS is the normalized throughput in million lines per second.
- n-1/n the performance gain relative to the previous revision
| # | Min[s] | Avg[s] | SD[s] | TotalAlloc [MiB] | Alloc [MiB] | NumGC [1] | LPS[1e6/s] | n-1/n [1] |
|---|---|---|---|---|---|---|---|---|
| rev0 | 24.976 | 26.083 | 0.821 | 16100 | 5144 | 33 | 0.730493 | 1 |
| rev2 | 18.285 | 19.509 | 1.400 | 16376 | 7360 | 19 | 0.997830 | 1.36 |
| rev3 | 10.668 | 11.366 | 0.451 | 17360 | 4677 | 24 | 1.710241 | 1.71 |
| rev4 | 10.312 | 11.495 | 0.541 | 17221 | 7107 | 23 | 1.769322 | 1.03 |
| rev5 | 8.781 | 9.765 | 0.425 | 17216 | 7072 | 22 | 2.077680 | 1.17 |
| rev6 | 9.235 | 9.651 | 0.421 | 16125 | 5155 | 27 | 1.975478 | 0.95 |
| rev7 | 8.155 | 8.531 | 0.228 | 11148 | 5713 | 17 | 2.237297 | 1.13 |
| rev8 | 6.644 | 7.039 | 0.296 | 11217 | 5788 | 18 | 2.745870 | 1.22 |
| rev9 | 3.880 | 4.102 | 0.0709 | 6590 | 81 | 129 | 4.702385 | 1.71 |
Figure 1 shows the previous table runtime data graphically as a box-and-whisker plot. It illustrates the progress we’ve made from the initial port with Revision 0 through nine revisions following up to Revision 9.
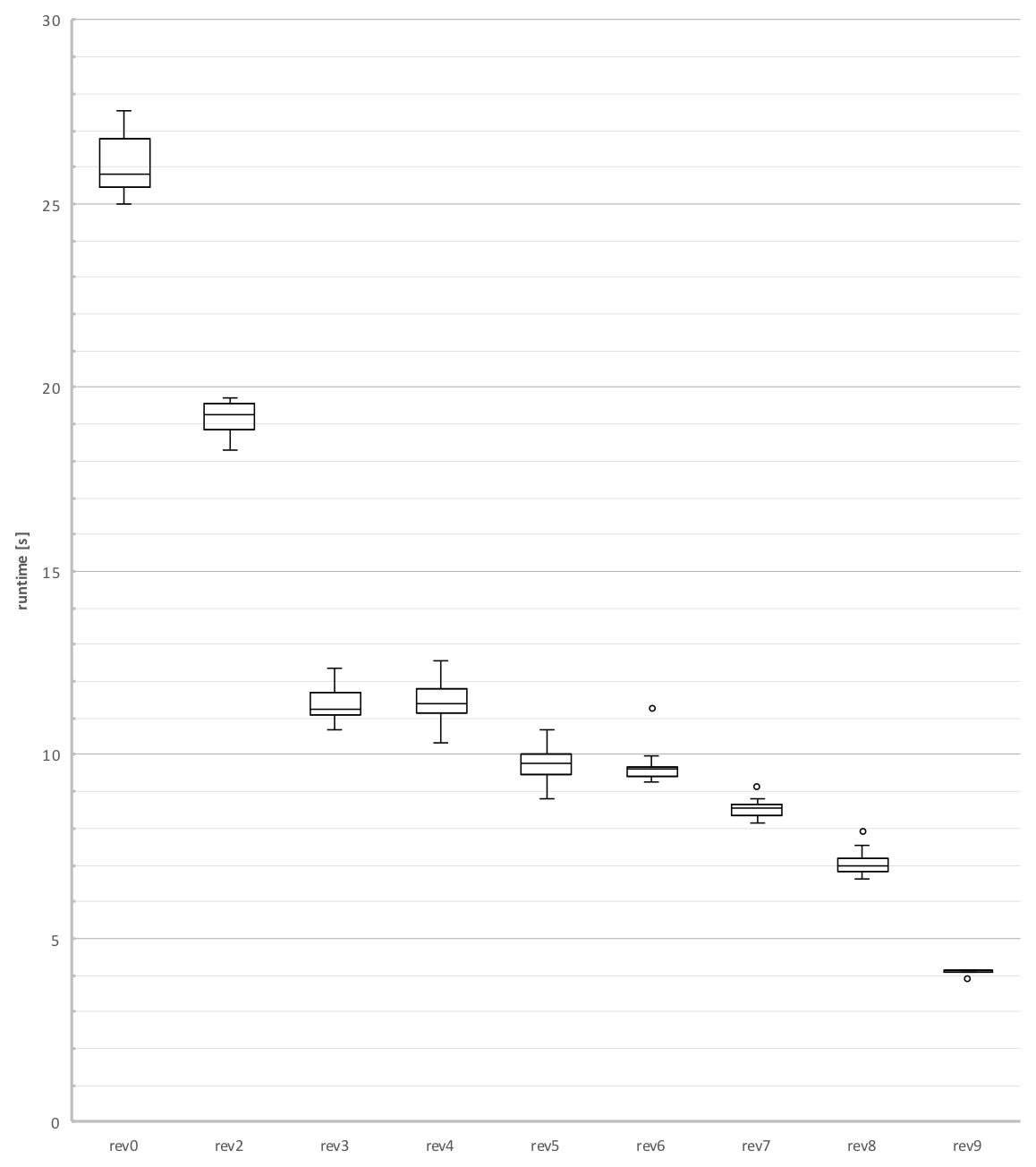
Conclusion – ‘Hitting the Wall’
We clearly hit a wall here with Revision 9. A runtime of 3.88 seconds for these 18.2 million lines of data is kind of impressive compared to other versions. I didn’t expect to get down to this number.
So, why do we hit the wall here? In Going Further we discover that the plain reading of all lines takes nearly the same amount of time as to process these lines, about 3.56 seconds (see below for details). Knowing this, we have to conclude that we can’t get below these 3.56 seconds as we can’t read the file faster. This is where we hit the wall and this is the benchmark for our challenge.
Saying this, I think we have two options to go even faster, perhaps only a few fractions of a second. First, we have to check if we can read the file faster. We haven’t done any optimization of the file reading and just used a bufio.Scanner to read lines. Second, we still allocate twice the memory we read from the data file. These two points might end in the same last optimisation because to read the file faster perhaps means to allocate less memory. We can’t read less memory than these 3.3GiB, or perhaps we can? There is a schema for the FEC CSV file, and we might jump right into the portion of our file where we know data is located. See Exercises for more on this.
That's an interesting challenge! Any more variations? As a rule of thumb, when you optimize an algorithm, there's a factor of 10 to find
— José Paumard (@JosePaumard) January 13, 2019
We produced a little monster of code and we ran it to an interesting point. Even if this challenge is not a serious thing, it shows what can be done; at all costs! Performance is one aspect of quality of code. The quality in terms of readability, maintainability and robustness against changing requirements is another and similar important.
But imagine, regardless of the silly challenge, when a tasks performance has impact on real stuff, peoples or animals lives, money, or any other matter of real value, then, every second might count and then performance at any cost can be justified, even if the code looks awfull, right?
That might be true. But you also have to take into account that, when you’ve delivered this optimized and highly performant code, you have to ensure that any change on your code doesn’t endanger anyone depending on it. So think about this when optimizing at all costs. Any further change might harm others when you left the company or the project and such a change ends in ‘SHTF’ and you might have to come back to clean up all that.
Exercices
Here are some exercices to go futher. These are points I was unable to integrate into this article.
- Read the file concurrently from two goroutines (hint: use a io.SectionReader) => what happens? Why is this a good/bad idea for a SSD and/or a HDD?
- Try to achieve (nearly) zero-copy of the strings read from the file and then use them in the resulting lists / frequency tables. “reading” the file with scanner.Bytes() instead of scanner.Text() only takes 2 seconds. Try to use that to break the wall. How can you do it?
- Make Variation7 in Java as fast as our Revision 9 in Go, that should be possible as there is no magic happening here.
- Revision 2 has a Bug, fix it!
- We violated c4 of the Challenge and eliminated the names list. Try to implement that back with as little peformance impact as possible.
- Disable the GC, what happens? Why?
- Write Revision 10 in Idiomatic Go, is it still “fast”?
Appendix A
A1 – Going Further?
To get an indication where we are now performance wise, we can do a few things. We can measure how long it would take just to read the 18.2 million lines of data and measure the reading of lines without its processing. With that we get a baseline where we are at its bare minimum of processing, like no processing. We would obiviously not go below this number, right?
# remove the processing goroutine and..
$ go run ./rev9/readfile9.go
Most common name time: 3.568166257s
$
It takes 3.56 seconds to just read the lines with scanner.Text() and do nothing with them. Compare that to our best run of 3.88 seconds. We don’t process 18 million lines in the other 0.28 seconds. Instead the lines are processed nearly at the same time as we read them concurrently in an another goroutine and hand the chunk of lines off to a processing goroutines concurrently. That is most probably our wall we hit here. The disk, or in our performance runs, the OS disk cache, is our limiting factor.
When we look at the memory behaviour
Alloc = 0 MiB TotalAlloc = 3540 MiB Sys = 68 MiB NumGC = 932
it seems we copy our data file of 3.3GB in size about once within scanner.Text(). Later we’ll see that all other revisions allocate at least two times this size. scanner.Text() copies the byte-buffer from an io.Reader to form a string and return it. How much memory do we allocate using solely scanner.Bytes()? Lets see
Most common name time: 2.392783786s
Alloc = 0 MiB TotalAlloc = 0 MiB Sys = 66 MiB NumGC = 0
None! Here we are. I assume if we want to go below 3.88 seconds this is the attacking angle in, to break this limit.
A2 – Concurrency Variations
With Go its easy to limit the available CPU cores to a Go program. Its a matter of setting the GOMAXPROCS environment variable before running the compiled program.
go with 1 CPU Core
$ GOMAXPROCS=1 go run ./rev9/readfile9.go itcont.txt
Most common name time: 12.006801212s
$
and with 2 CPU Cores
$ GOMAXPROCS=2 go run ./rev9/readfile9.go itcont.txt
Most common name time: 6.409553051s
$
we take about half of that.
$ GOMAXPROCS=3 go run ./rev9/readfile9.go itcont.txt
Most common name time: 4.5708305s
$
we are right at about 4.5 seconds. Think about what that means. One of the other implementations had a runtime of about 12.5 seconds, but as far as I can see without any concurrent or parallel processing of what was read from the file. Does this correlate with our meausurement of 12s here?
Appendix B
B1 – Get the Code
https://github.com/marcellanz/file-read-challenge-go
B1 – Other Implementations
- Philippe Marschall, A Reimplementation using Eclipse Collections and marschall/mini-csv
- Marschall reports a runtime “to about 10 seconds” on a Intel Core i7-7700T (Desktop). Variation7 ran in about 18-19 seconds on his machine. With 23s on my MacBook Pro (I7-7920HQ) I read a factor of 25%, so Marschall’s 10 seconds might be about 12.5 seconds of ours.
- Gabriele Bianchet-David, in Rust, runs for about 1-2 minutes
- Morgen Peschke, Variations in Scala, ran on my Laptop with
- Scala StdLib – 37.103s
- Akka Streams – 53.507s
- Java StdLib – 63.921s
B1.1 – Other Implementations, After Publication
- 2019-04-04, Denis posted this after my blog post. He is using his “ldetool”, a Generator of fast log file parsers written in Go, and it runs the challenge in
"revision: mineislarger, runtime: 1.837077615s"and with disk cache cleared"revision: mineislarger, runtime: 2.812756462s"and its just over 430 lines of code, impressive! - 2019-05-08, Ben E. C. Boyter published a nice blog post and went from this article (took Exercice #3) and worked through different and interesting angles to find better performance with JAVA.
B2 – Memory Allocation
$ GODEBUG=gctrace=1 go run ./revX/readlineX.go
rev0: gc 33 @22.877s 2%: 0.007+1321+0.043 ms clock, 0.057+15/1990/29+0.34 ms cpu, 6544->6544->4198 MB, 6556 MB goal, 8 P
rev1: gc 18 @21.921s 45%: 8.0+14368+9.0 ms clock, 64+73938/24847/0+72 ms cpu, 4322->4447->3709 MB, 4380 MB goal, 8 P
rev2: gc 19 @13.833s 7%: 0.88+1100+0.40 ms clock, 7.0+2780/2199/1576+3.2 ms cpu, 7171->7261->4510 MB, 7355 MB goal, 8 P
rev3: gc 24 @12.147s 14%: 193+747+0.059 ms clock, 1547+2410/1493/722+0.47 ms cpu, 6901->7065->4586 MB, 7228 MB goal, 8 P
rev4: gc 24 @11.941s 15%: 475+629+0.068 ms clock, 3807+1342/1256/1823+0.54 ms cpu, 6762->6819->4340 MB, 6995 MB goal, 8 P
rev5: gc 22 @8.404s 11%: 0.027+473+0.057 ms clock, 0.21+1117/942/389+0.46 ms cpu, 6804->6954->4171 MB, 7100 MB goal, 8 P
rev6: gc 22 @12.260s 12%: 185+694+0.12 ms clock, 1481+2120/1386/1136+1.0 ms cpu, 6635->6778->4401 MB, 6998 MB goal, 8 P
rev7: gc 17 @9.341s 9%: 72+819+0.34 ms clock, 583+1958/787/514+2.7 ms cpu, 5928->5929->4380 MB, 5929 MB goal, 8 P
rev8: gc 18 @6.637s 7%: 0.019+425+0.079 ms clock, 0.15+303/843/892+0.63 ms cpu, 5639->5761->4200 MB, 5807 MB goal, 8 P
rev9: gc 129 @4.391s 3%: 0.006+3.6+0.044 ms clock, 0.052+2.8/6.1/1.9+0.35 ms cpu, 130->131->49 MB, 133 MB goal, 8 P
# using runtime.ReadMemStats()
rev0: Alloc = 5144 MiB TotalAlloc = 16100 MiB Sys = 7279 MiB NumGC = 33
rev2: Alloc = 7360 MiB TotalAlloc = 16376 MiB Sys = 9360 MiB NumGC = 19
rev3: Alloc = 4677 MiB TotalAlloc = 17360 MiB Sys = 7944 MiB NumGC = 24
rev4: Alloc = 7107 MiB TotalAlloc = 17221 MiB Sys = 8007 MiB NumGC = 23
rev5: Alloc = 7072 MiB TotalAlloc = 17216 MiB Sys = 8007 MiB NumGC = 22
rev6: Alloc = 5155 MiB TotalAlloc = 16125 MiB Sys = 7679 MiB NumGC = 27
rev7: Alloc = 5713 MiB TotalAlloc = 11148 MiB Sys = 6983 MiB NumGC = 17
rev8: Alloc = 5788 MiB TotalAlloc = 11217 MiB Sys = 7116 MiB NumGC = 18
rev9: Alloc = 81 MiB TotalAlloc = 6590 MiB Sys = 205 MiB NumGC = 129
B3 – Turn off Spotlight
# to turn off Spotlight on MacOS
$ sudo mdutil -a -i off
# and turn it on again
$ sudo mdutil -a -i on
B4 – GC Tracer in Detail
Let’s explain the diagram in detail, it will help us later to understand what happens with other revisions
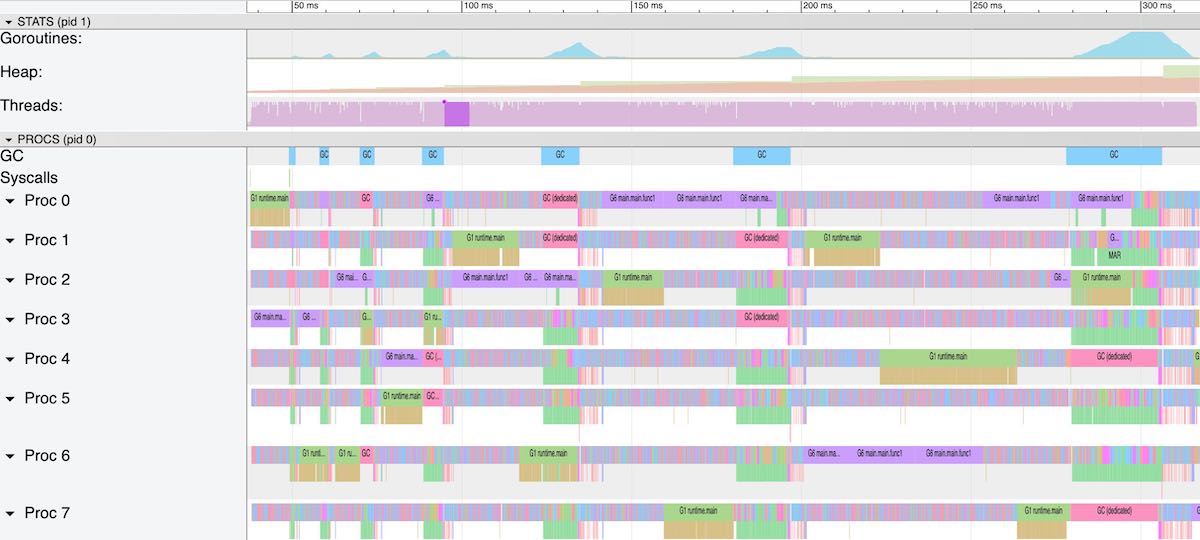
What we see here are the first few hundred milliseconds of revision 1. There are two main rows, STATS and PROCS. Under Goroutines STATS shows Runnable- and Running goroutines. Heap shows Allocated Heap Memory together with the NextGC target and Threads the running OS threads (yes Go use threads, goroutine are scheduled over N OS-threads where N is usually the number of CPU cores). The second column shows GC activity and then Proc n shows the processors where the goroutines are scheduled on.
Starting from the top on goroutines the kined of blue waves right at the time when the GC is running with 7 times with increasing duration. Wave 4 and 5 have about 5k goroutines in Runnable state, but they don’t run here as GC seems to block them a bit. The 6th and 7th wave have 10k and just over 12k runnable goroutines. The GC is not the limiting factor in our run as we’ll see later. Relative to its runtime, GC runtime is irrelevant.
Starting in Proc 0 there is a goroutine named G1 runtime.main, it is our main function (even not started as a goroutines itself, it is a Goroutine). G1 is running small spikes of systemcalls syscal.read(), that can be seen as orange blocks below the G1 goroutine. Here our program reads data from the file using bufio.Scanner and its scanner.Text() method. G1 is buffering lines of data and then fires off goroutines to parse the lines for names, firstnames and donation dates which is exactly what we planned to do.
these goroutine names are so silly because we have a one method implementation with no names for the goroutines given.
G6 main.main.func1 is our for – select block, where we receive the three parsed data fields and then append them to the three lists. All other processors have thousands of goroutines running. We can see the behaviour we expected. G1 reads lines of data, fires off new goroutines to parse them and then feeds them over the three channels. Our CPU cores seem to be fully saturated with “workload”. Unfortunately its the wrong kind of work they’re on, its a lot of coordination sending and receiving messages over three channels, beside some time to parse the lines.
